Here we discuss one of the latest paper in 2025 in AI from Google Research given in [1] reference. The paper is titled, “Nested learning: The illusion of deep learning architectures” and is published in “Neural Information Processing Systems” . The contributors are: Behrouz, A., Razaviyayn, M., Zhong, P., & Mirrokni, V.
The Authors suggest that the very function of the human brain is neither sequential nor linear. That is, different waves emerge from the brain at different times, and learning occurs in different phases, from high-learning neurons to slow-learning neurons. This strongly suggests that Nested Learning (NL) is more favourable to the learning paradigm of the human brain, whereas in LLMs, only linear layers with varying parameters are not the foundation of learning. In deep learning today, changes often involve adding more layers, which do not alter the area the model is intended to learn, even when providing more pre- or post-training data. Some suggest that the optimizer needs to be intelligently chosen for such learning; however, the authors differ on this point. NL is based on these facts, and new learnings can’t be made to LLMs after they have been sufficiently trained. All LLM know is the data and knowledge presented to the MLP and new context window as temporary memory in which LLM works.
In the first part of the paper, the author discusses human learning as associative learning and how this can be viewed as Nested Learning.
What is learning in Neural Networks?
Here, the very basics of learning, it all starts with gradient descent, given the objective function,
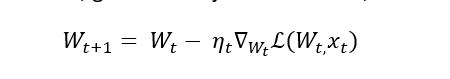
Which the author proved equal to,
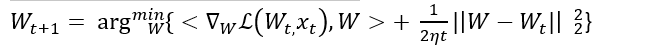
In [1], the authors specify, “Memory is a neural update caused by input, so learning is a process of acquiring useful memory.”
The author claims that many neural models can be decomposed into Nested Learning. In particular, associated learning and momentum-based learning are presented.
What is associative learning?
Here we have keys and each key maps to a value. The explanation given in this paper is broad; the keys can be tokens, as is generally thought of, or they can be phrases, other memories, or even gradients themselves.
Given a key k, say a memory, a value is triggered in the brain v, and for a query q, an output is generated.


This is mathematically given in [1] as follows:

What is momentum in learning?
The architectural decomposition in momentum-based learning is projected as follows:
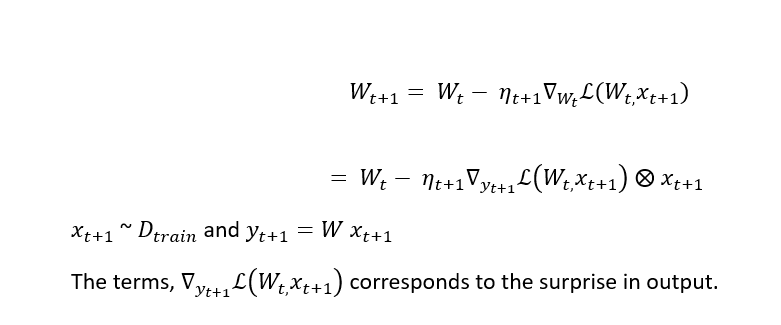

The gradient term does not depend on the output of the recurrence in the above equation. This shows the momentum term as values less associative memory and leads to more than one level in learning.
To be continued…
Subscribe for updates..
References
[1] Behrouz, A., Razaviyayn, M., Zhong, P., & Mirrokni, V. (2025). Nested learning: The illusion of deep learning architectures. In The Thirty-ninth Annual Conference on Neural Information Processing Systems.
