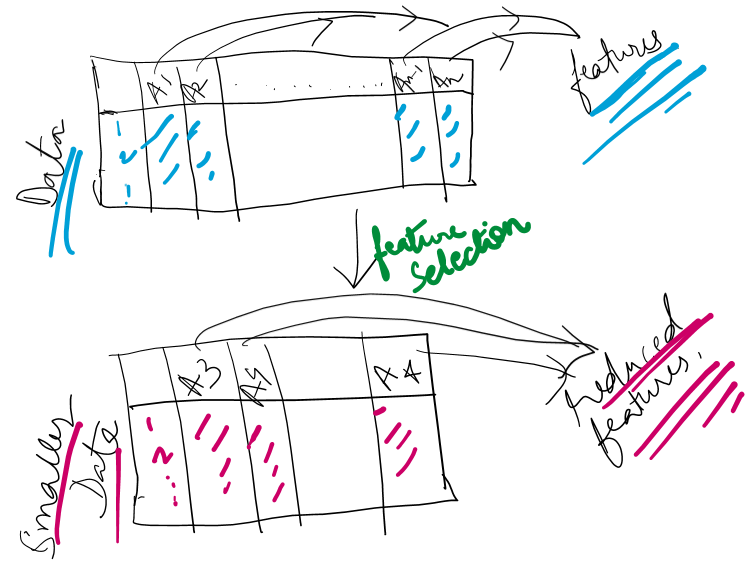
In machine learning and data science, feature selection techniques are used often to find the most relevant attributes defining the data.
What are the features of data?
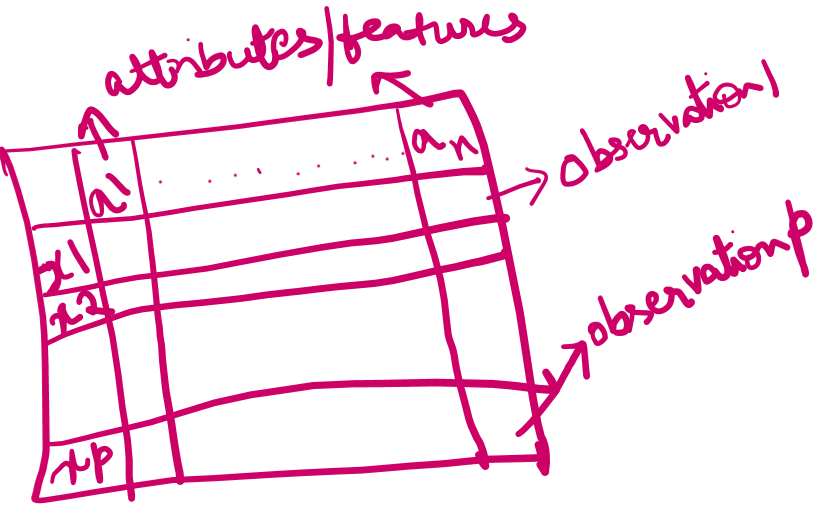
The data for use in Machine Learning is typically in the form of rows and columns. The rows define the values for a particular observation, while the columns define the attributes in which these observations are computed.
Features or attributes define the observations.
They describe properties of data such as the value of climate, temperature, pressure, humidity, and so on in case the data is weather data.
In case data is of human resources for interviewing a candidate for a job, here the attribute would be like, name, age, gender, height, education, experience, degree, and so on
More such examples can be framed out.
Are all datasets in this form?
No, they need to be put in this form to use certain algorithms. An example is text data which needs to be put in this form using techniques such as tf-idfs, LSA, and so on.
Why feature selection?
Feature selection is used for the following reasons:
- Taking the most important features from the data.
- Reducing the data and hence reducing the complexity of processing.
- Reduced data in fewer dimensions affects computational processing largely especially in problems like SVMs which need to go to higher dimensions to compute the separating hyperplanes.
- Reduced data helps to make use of geometry to understand what is happening more clearly.
- Noise is reduced as well, in this process.
- Better computations of accuracy on the refined data.
…
How to do feature selection?
The following are popular feature selection techniques:
Filter methods,
Wrapper methods, and
Embedded methods… to be continued
