Note: The article in duplicate is present on authors other social media accounts as well.
Let us first consider the open internet case, wherein the internet can be used to improve the results of an LLM.
Now, there are cases when the LLM was trained and in this time some new information has been collected. An example of new information since say GPT 3.5, was updated/trained is “Odysseus Moon Landing By a US Private Company”. When searching about it on an LLM it may refer to something else.
Let’s see what chatGPT says about this event:
Here is the search on GPT3.5, using the free version of GPT: ChatGPT (openai.com)
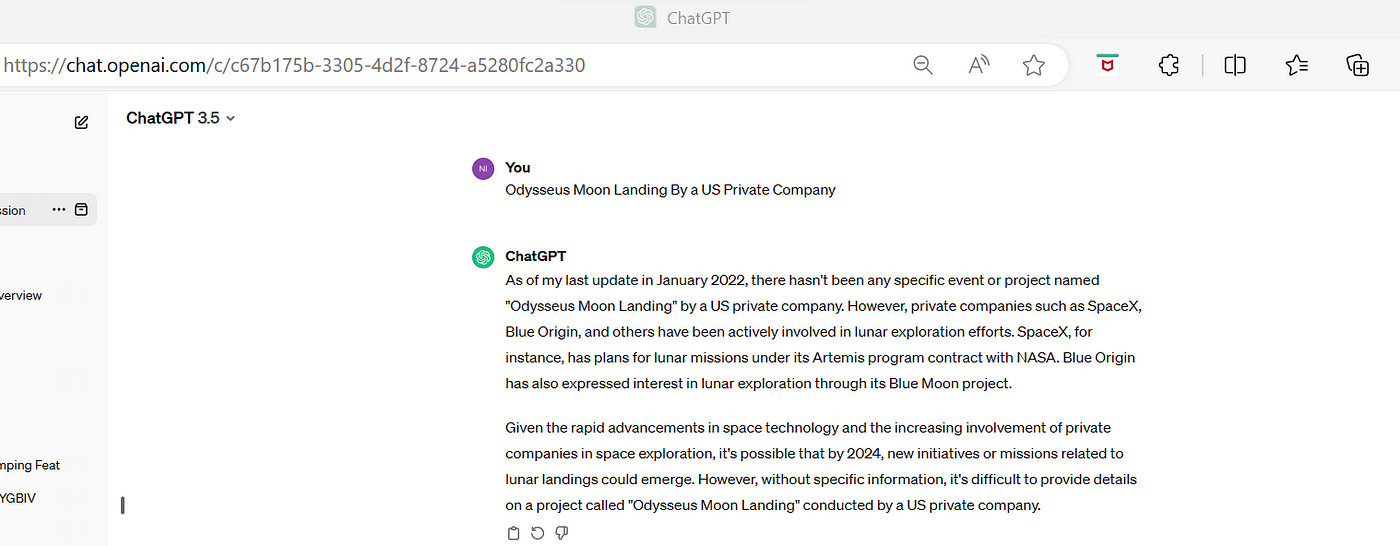
So, chatGPT says it does not know of this mission!
While here are the latest updates to this space mission: All About The Historic Odysseus Moon Landing By This US Private Company (msn.com)
Here chatGPT is quite unaware of the fact that after decades USA landed on the Moon again! As it was last updated before this mission of USA was successful.
It’s not GPT’s fault, here comes the use of The RAGs (Retrieval Augmented Generation) where the information flows as follows in case information is missing from the LLM model.
Step 1. User query sent to retriever.
Step 2. The results and query are sent to LLM.
Step 3. LLM processes the new prompt which is an amalgamation of the user query + the retrieval results.
Step 4. The new answer is generated by LLMs’ great text construction skills with more data fed into if as in Step 3.
—
This was the open internet case.
The other case is closed search space. This includes places where the information is in closed domains, for example, the information is regarding the products and their manuals and for example, the replies to the customers by an application engineer at the backend of a customer call.
Here, internal documents can be channeled into the query of the customer which is then sent to an LLM to generate a nice worded output to be sent to the customer.
—
Some merits and some drawbacks of RAGs.
When new data was present on the retriever, here LLM was used just as a Language generator, however, LLM is a big power, so its power is not unleased to the full in this context.
Here is how chatGPT replied when retrieved information from the internet was sent to the prompt:
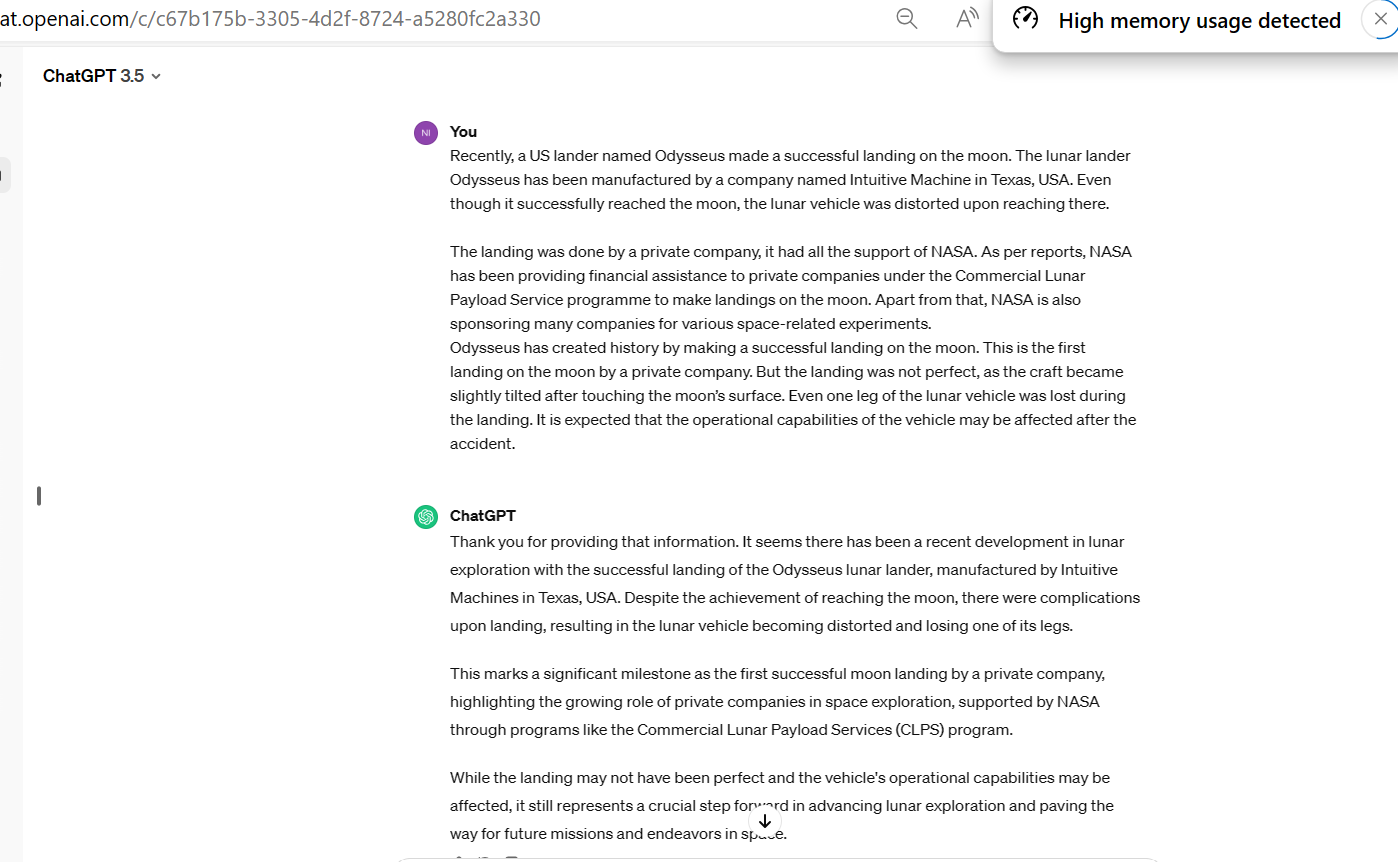
-LLM is powerful.
-chatbots based on LLMs must have a way to enter such links of retrieval results into LLMs model as inputs, this way the first text output of the above chatGPT won’t come, which is to say,
“Thank you for providing that information. It seems there has been a recent development in lunar exploration with the successful landing of the Odysseus lunar lander, manufactured by Intuitive”.
This line is not needed if the LLMs regularly take feedback, links, file dumps from outside.
-This can be a dialogue box taking in the links, or, the way to upload documents that are required, in case of closed search problems.
-In all RAG can be built into the chatbots using LLMs with the enhancement to search the web in case of missing information.
–Here LLM with RAGs seems to generate valuable texts only, and not much information is generated by LLMs as given above in Odysseus’ lunar lander example. All information from the links is looked at and well-documented by LLM.
-We need more for sure! LLMs are powerful tools.
So here are some points!
1.Can LLMs like chatGPT provide a provision to dump in files there in privacy/public mode (as the use case may be) to improve search results and hence the LLM outputs?
2. And in an open internet case, can LLMs allow adding some links to its repository, to be able to function as one unit on its own?
3. Why not scrape the internet on its own, when information is missing or to be updated? It would add more power to bots. LLM can then reason more symbolically and more reasonably.
4. Why not integrate the web search unit in the LLM model provider such as chatGPT?
Retrieval Augmented Generation mostly uses LLMs to generate text from a collection of new information while LLMs can do more? LLMs are much more powerful!
To be continued…
