Note: The article is present on author’s other social media accounts as well.
Abstract
Here is a summary of the some ways which may effect the results in ML/DL/LLM to the betterment. We always want the results to improve, in this quest comes the use of information. Yes, one way is to find new network used in these problems, finding a network may take time, and using same data, or even more data is proving to bring no new results, or results that are very less significant to be called a “growth” in experiments. Some suggest new data wave should be looked at, yes that has to be done on a continuous way, since new data, would soothe the new knowledge that has grown around the world in this time lapse. Hence, an incremental increase in data being fed to a network is a must which means new models would keep growing up, either as patch to the old network or as a lump sum full models when patches oversize themselves.
Here in this article is defined the possibilities of using information at right time apart form data which may improve the results. However, it must be noted since saturation in results have happened so its time to review the network architecture and the algorithms used in this process to achieve more robust solutions and human like understanding that is expected form the models both in gen AI, other DL problems and even in LLM.
Detailed Explanation
As the amount of data is increasing exponentially, how to measure the improvements made in the by a new model. Well, some say, since the data is growing exponentially so it should not limit the models capabilities. The point is, as long as same kind of data is given, same outputs shall continue to be produced. Yes data is growing exponentially as are newer terms, newer slangs, and news technologies, but pattern produced would logically be same. This can be measured by the outputs generated. The output generated can also project light on information generated by the new dataset. However, since data is new, and enormous GPUs are used to compute the results, but pattern is same, hence we are limited to same kind of results, and hence the same kind of information that is being produced. But as mentioned before new data shall always be required to be put up to keep with with newer information about a product, about world or even about languages such as slangs in a particular language and their particular use.
A typical ML/DL/LLM problem looks like as in the following figure (Fig 1):
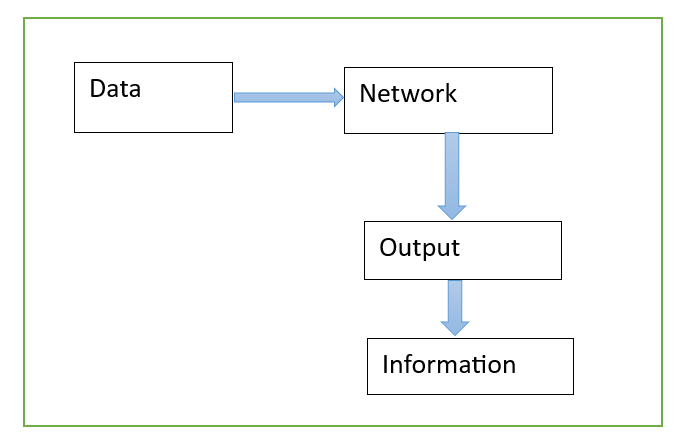
A model shall be better than previous if there is more information and this can be measured by the correctness in viable results on benchmark datasets. How to measure it? By a way of correctness or improvement in results, accuracy, precision? This can be considered as information generated by the model, either by a change in new data added to it or by the change in the backbone of model used, yes the algorithm.
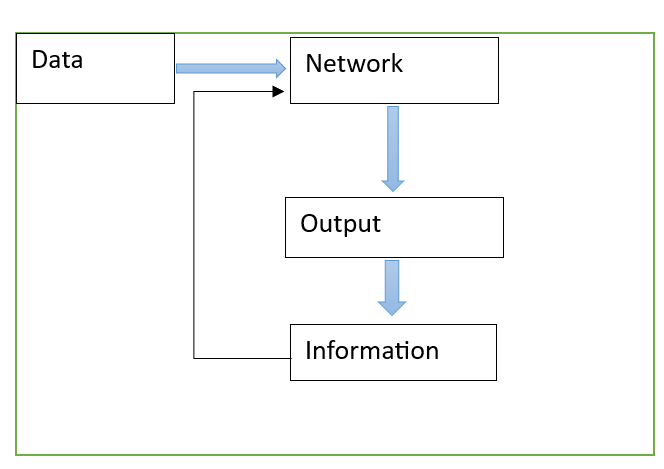
The information produced by model (data + network) can be send back to the network to be used in next phase. This happens in many kind of algorithms even now, for example, while selecting minimal keywords in text data problem, we may use SVM to classify the accuracy with a current feature set and to improve the selected keywords with this knowledge as well as initial data. Such methods are called wrapper methods, which use an information which is classification ability of the selected keywords to be used to decide the next subset of features. In some problems this is called fitness ability of a feature set.
Here is the pictorial representation of this.
So why we need to still go on? As we need to still build models that can understand- NO not to take away jobs! There is enough tasks that need to be done and one must think of a bigger picture, wherein Sky is the limit.
So back to this discussion. Here is an example of a still existing flaw in 2023 where there still needs improvements in ML/DL/LLM models.
Example: As I gave this example in previous article as well. The command says “put blue color in the cap”, but the algorithm does not put blue color in cap, it puts blue color somewhere else in the image file. Note the information was there but it was not understood. So, we need to feed in information in the Network apart from raw data. There are two things:
- Outside world information, and
- Information generated by the model.
Information generated by the model can be used as a criterion to see how much better the new model has become in solving proprietary problems in all domains touched by the data. This can be termed as the “surprize” in data.
And if there is no new information generated by this new data, or not as much new information as was essential to mark the new data as useful. Then? Well then its time to delve in the creative step, to understand what is being missed out ? Or better to say, where can we put the right parts to improve the algorithm, such as the Transformer itself, though it was the best state of art method which was used at that time.
Yes, “we don’t need to sit back and wait for the new wave of data”, as said by an AI enthusiast to me. Yes right, so this marks the journey in one of the following three directions:
- New data.
- New “creative step” in the model building process.
- New information to be fed to the models.
I have discussed points 1 and point 2, now lets discuss point 3 now. Lets consider Information not as an output of a model, but now as an input to model, this can be taken up as an exercise in AI till newer networks are build to support new data and new information.
Lets see it this way, information is processed data. It has more content than data itself. Since in ML/DL/LLM we preprocess data before sending it to a model. So this data itself has some information content, hence they can be referred to as information of say degree 0. And other information on top of this data can be fed to the ML/DL/LLM model. This information can be entropy, dimensions, relations to mention a few. For example, in the statement “Reki is standing near parking slot” and the information on top of this is that Reki is the Governor of New York, say for an example. Such kind of relations may be present later in the text too, but when such an example is provided upfront with the data, data here was “Reki is standing near parking lot” this makes input more enriched to perform better in any such tasks. This particular case can be considered as an information of degree 1, in same way similar information can be considered to be of degree 2 if it explains one more level of depth. This can be helpful to define understanding in data. These information need to be fed at right time and at right place. Here is the pictorial representation of this approach, where in outside world information is presented not as data but as information.
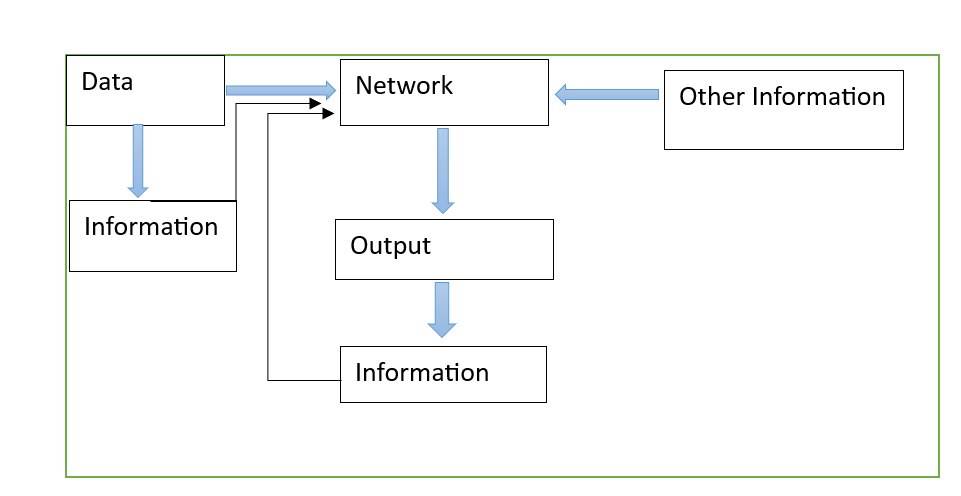
The Figure 3 shows, that information can be generated form data as well as the information can be provided apart form data, and some information is generated when the model processes and evaluates some data. The information generated by data can be an essential step too.
Again this is just a proposal till we build a newer form of networks to improve results. Aim is we need more understanding in AI models, how to do it? Adding more information and not just data, or by designing new networks and new algorithms? Providing the information can improve the results. But this would require experimental proofs, however theoretical proofs shall not be difficult to either, I have not tried either yet. Still when the model is given information + data as input the “surprize” in the model, that is new information content in the model should increase, still there is no experimental proofs yet, and as we know each run of LLM/DL costs a lot, hence it is suggested that scientists should try finding out theoretical proofs before proceeding further.
Reference
