#artificialintelligence #deeplearning #nlp #techenthusiast #ai
The new AI model by Google, as per its marketing team, it seem to be a serious enhancement in all AI models till date. The point is how real are these and what were the prompts given before the outputs were recorded.
Given in a message on the internet, Google confirmed some of its results were overhyped, BUT WHICH ALL?
Google faces controversy over edited Gemini AI demo video (msn.com)
And some news on the internet shows that Google accepted that it was hype. Here-
Google admits it edited AI Gemini video as it chases OpenAI (afr.com)
It can be tried in BARD as per the below link on google blog.
So I tested it on Bard only.
Google Bard: How to try the new Gemini AI model (blog.google)
Here is the YouTube video, that you can view to see the examples run on Gemini and the results in this video are really as never before gen AI results.
Hands-on with Gemini: Interacting with multimodal AI (youtube.com)
It can work with text, image files and even do coding.
Further, they have included the following in their document:
- Spatial reasoning and logic as a part of the achievements of Gemini as well.
- Image sequences- here sequences of images are used to see what Google AI would respond, and they respond it well. Magic tricks- Again image files and what is going on in changes in the image files is shown
- Vision to text capabilities- Again some games with yarn and glasses as if AI is attending a magician session.
The key is — all answers were right! Any prior prompts that were given here?
Some of the results improvements have been mentioned in their research results as follows:
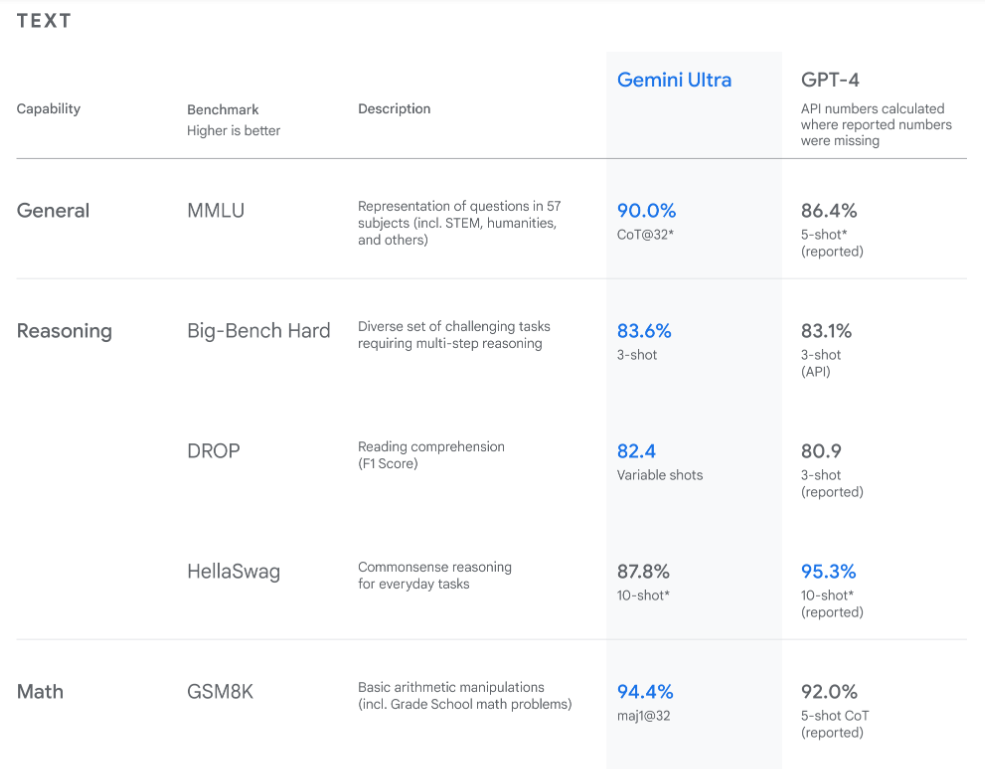
The above results are taken from:
Introducing Gemini: Google’s most capable AI model yet (blog.google)
Since, in one of the articles on the internet I read about Gemini being capable of much more, but how to really test it all?
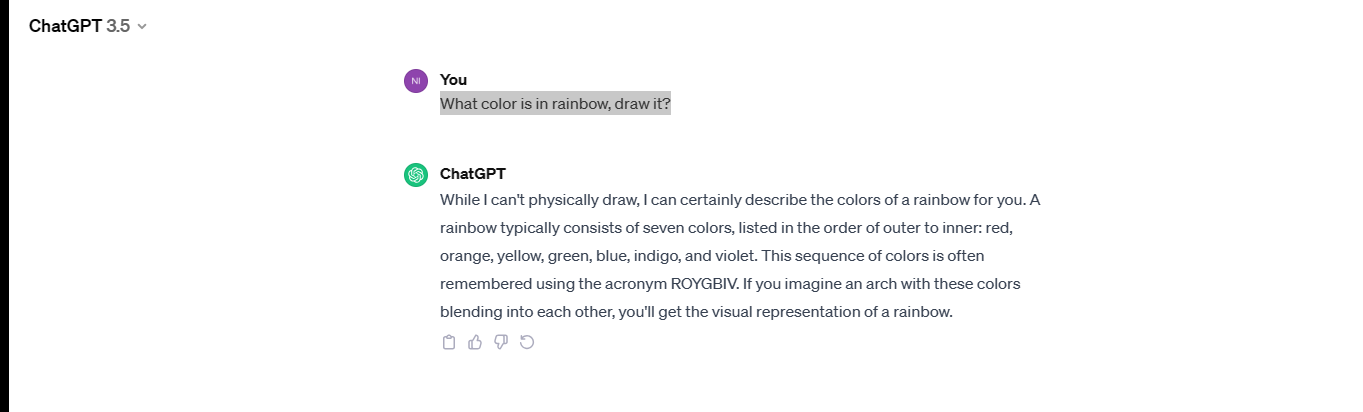
So lets try some on Gemini through as said above that its in Bard now, and now see queries results in chatGPT latest version.
Here is the first question to both, Bard (as told Gemini is in it) and chatGPT 3.5. So the question for both is: “ What color is in rainbow, draw it?”
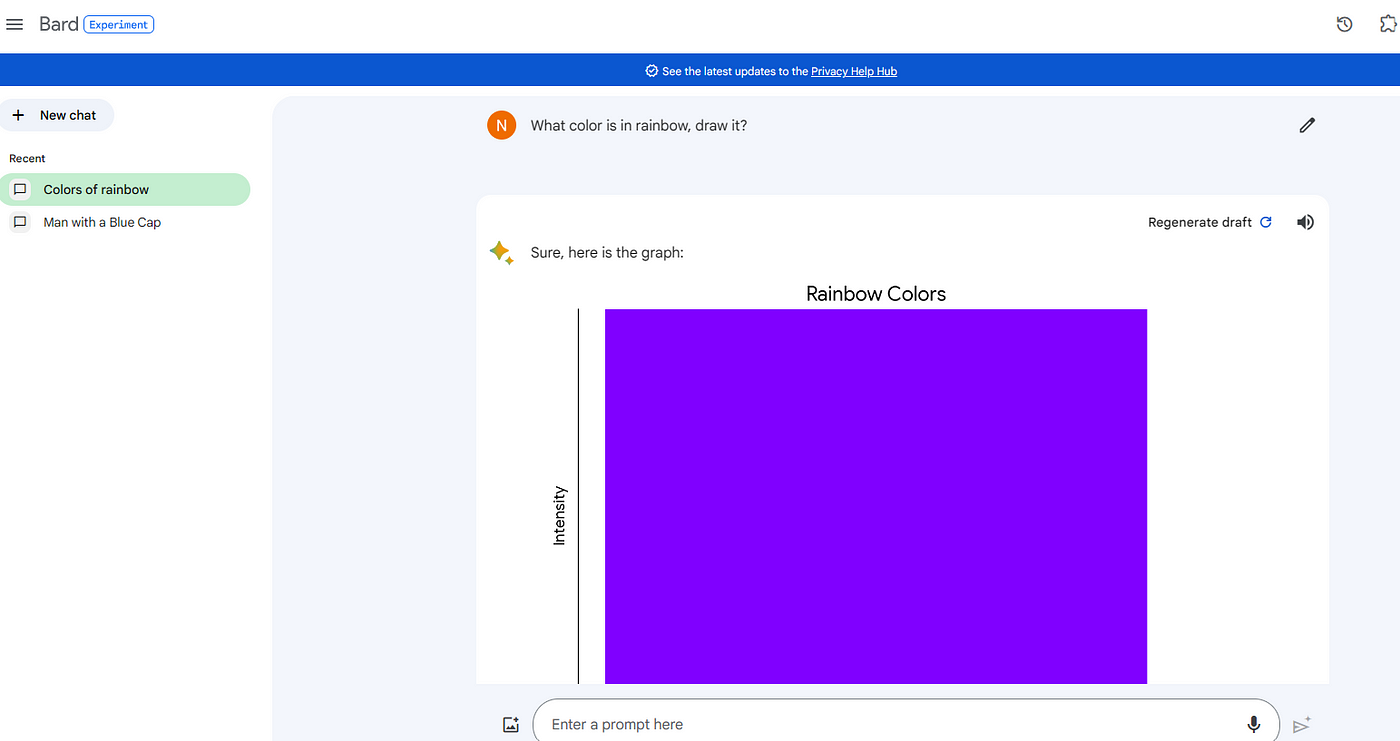
After doing the regenerate here is Bard output-
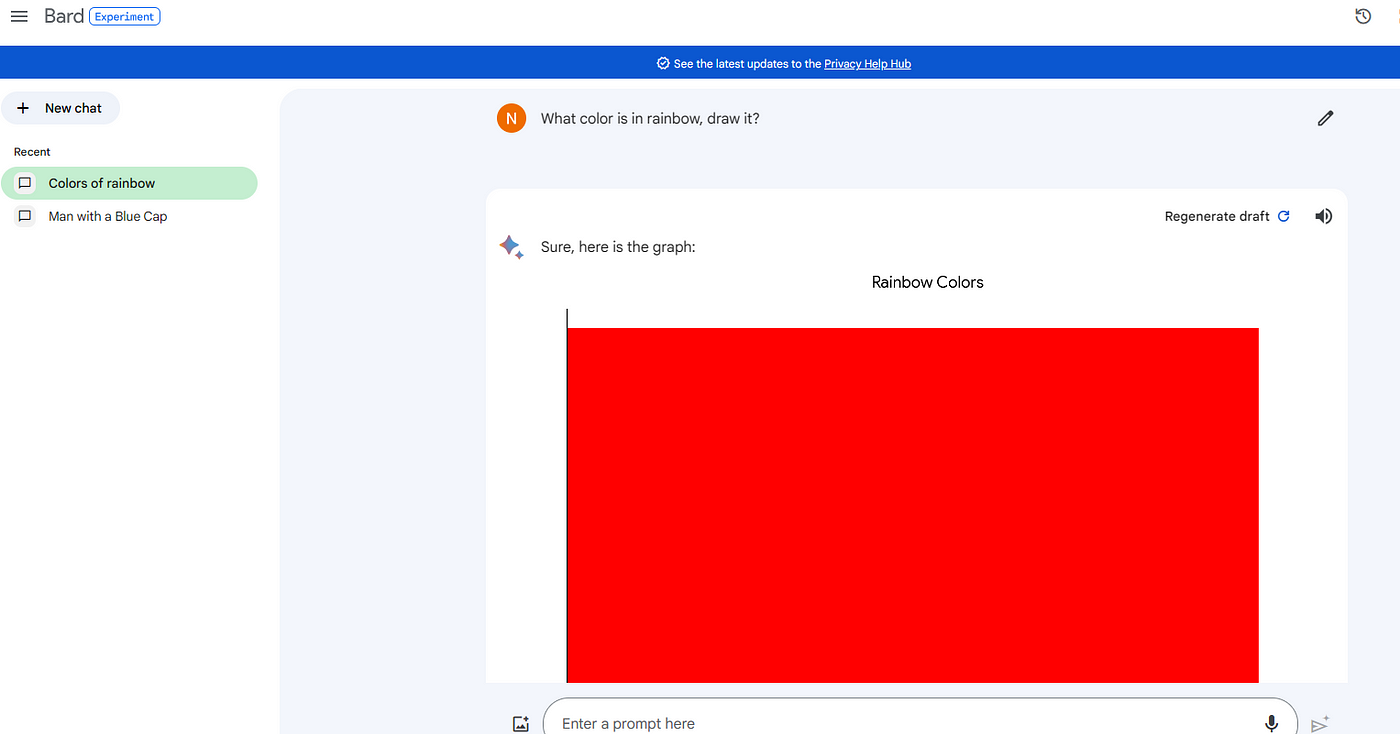
So, both don’t work with image together, and Bard shows weird output here. Well, I don’t want to test more on it. Still I thought to give another try on both Bard(as told it includes Gemini) and chatGPT, here,
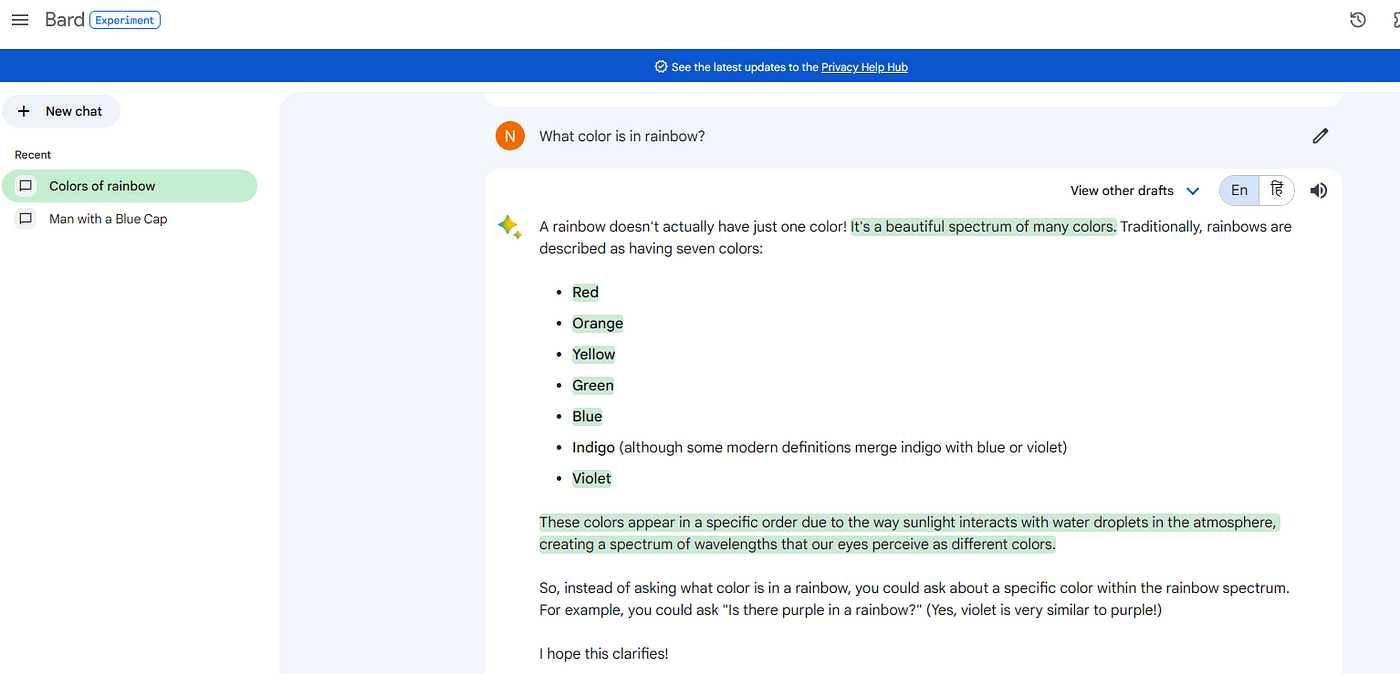
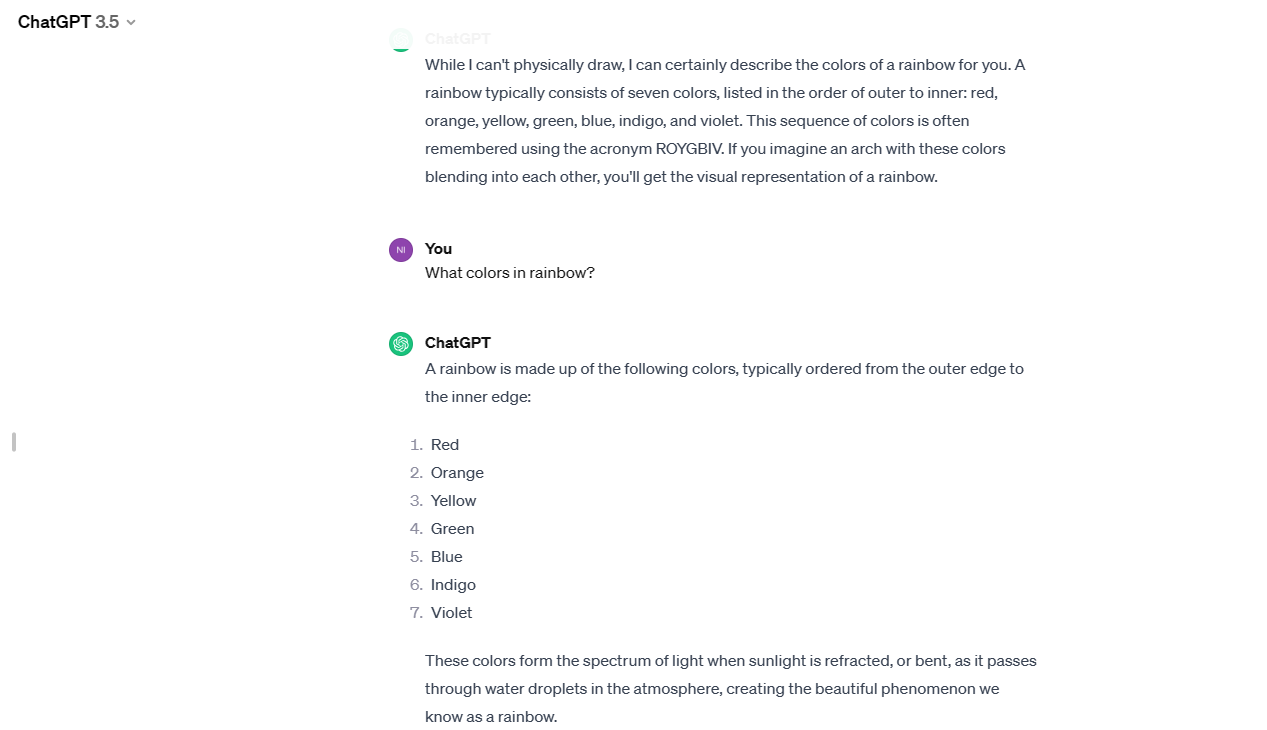
When asked direct question — “What colors in rainbow?”
Here are the results of both:
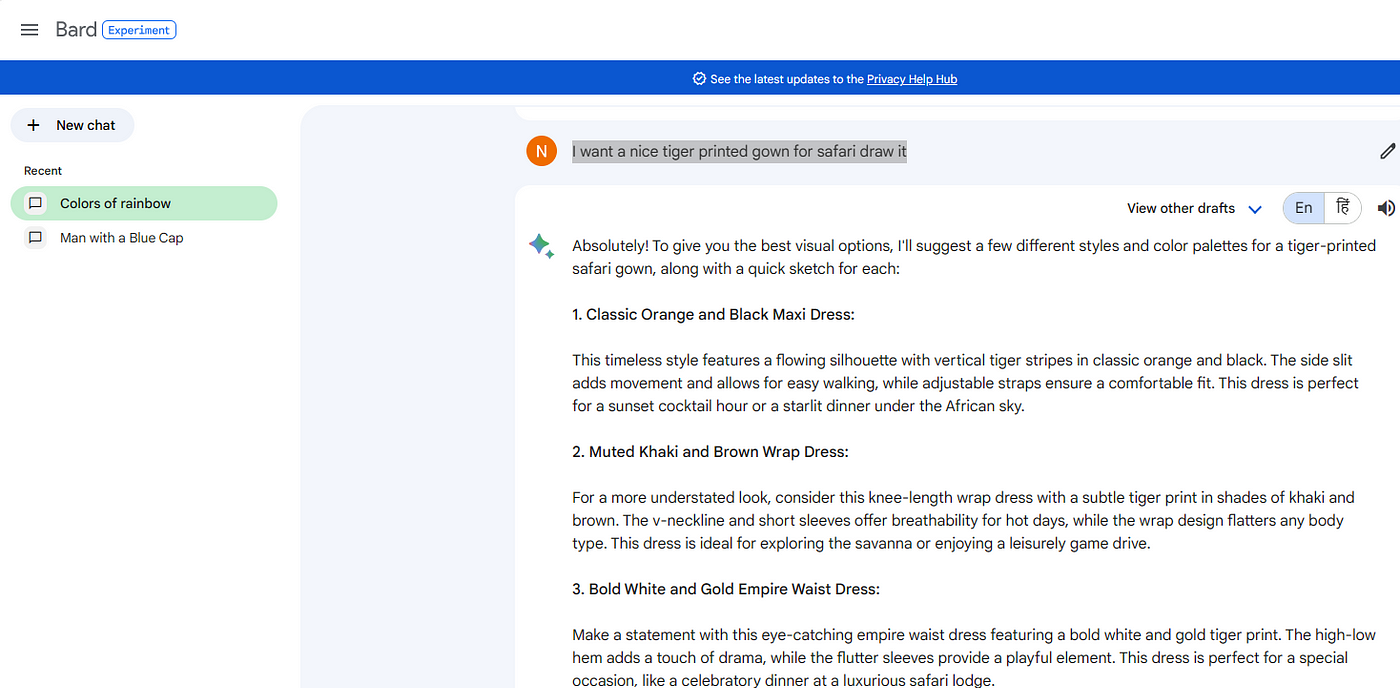
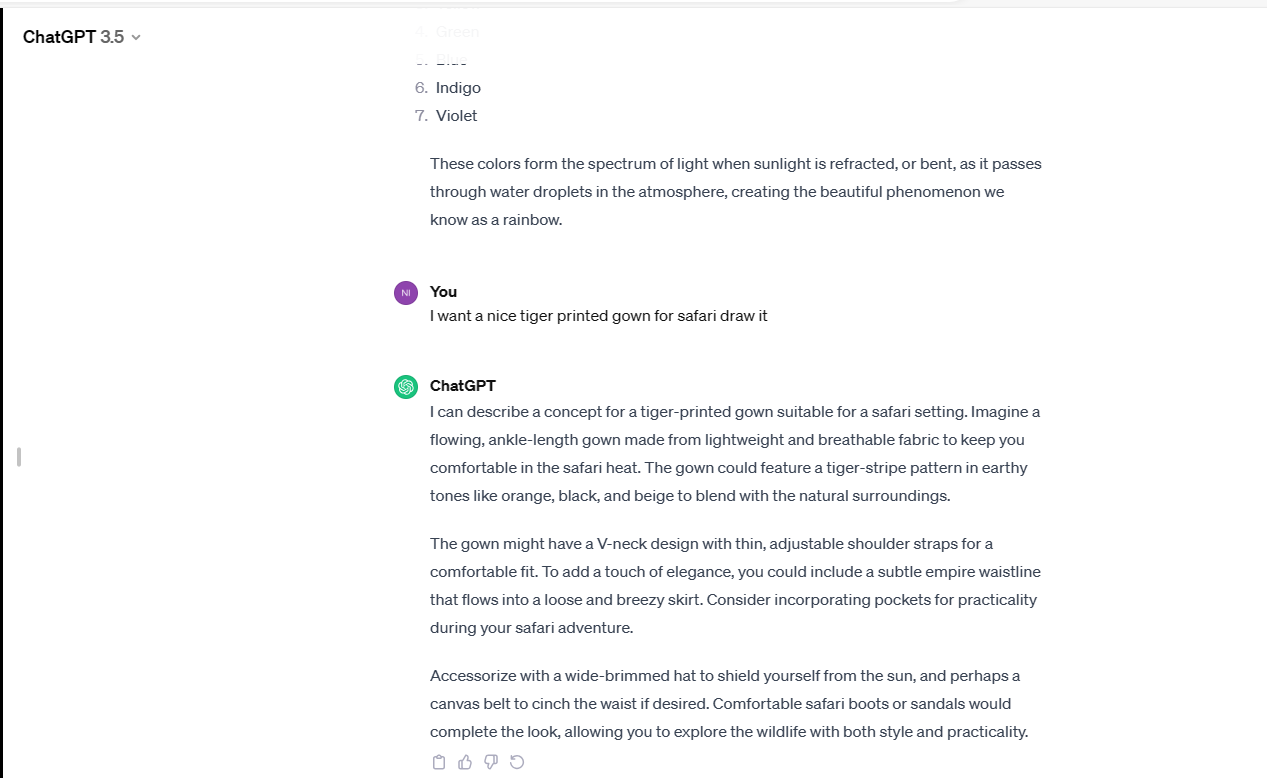
Another try here is: “I want a nice tiger printed gown for safari draw it”
And here is Dalle-e.2 results for the same.
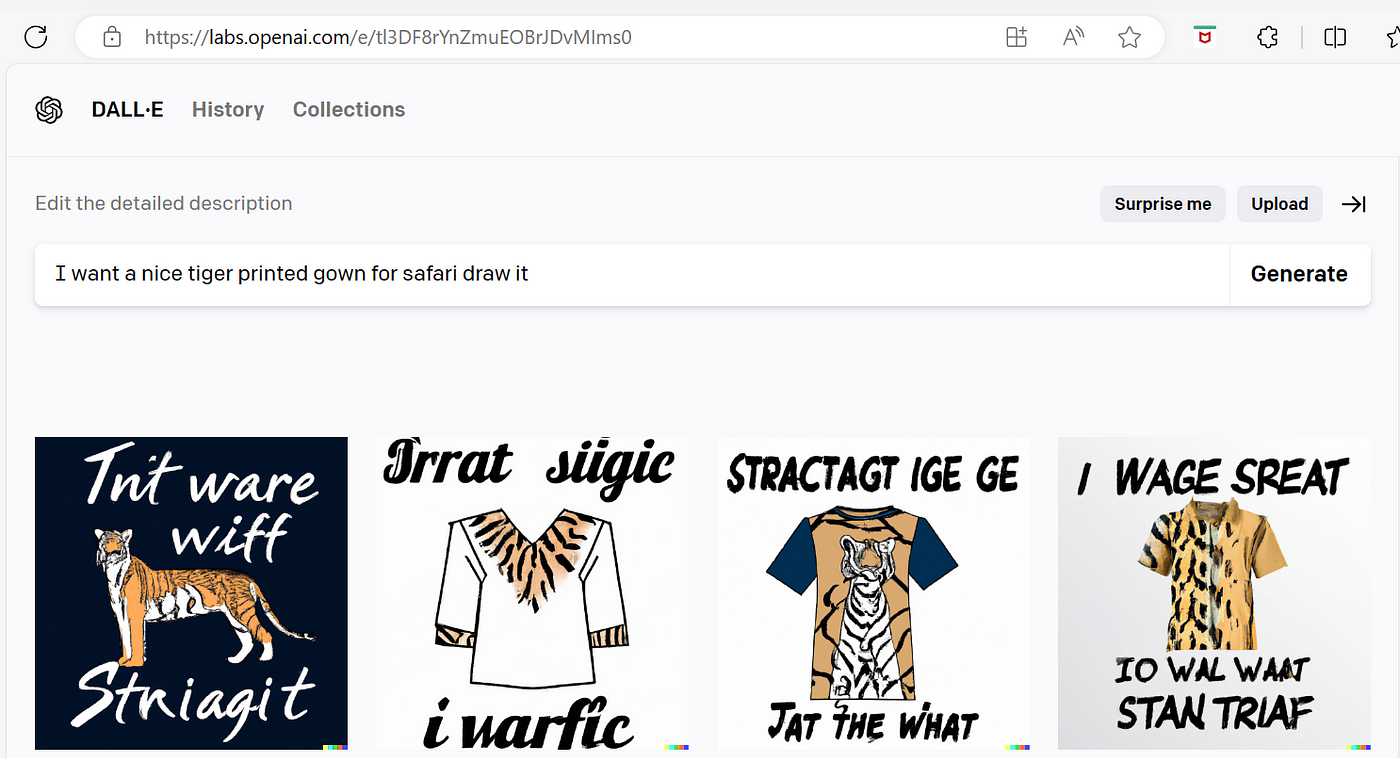
So, this is the current state.
I even tried AI Studio, My try with Google AI Studio-
I preferred not to enter payment information. And leave it for a while to be discussed later.
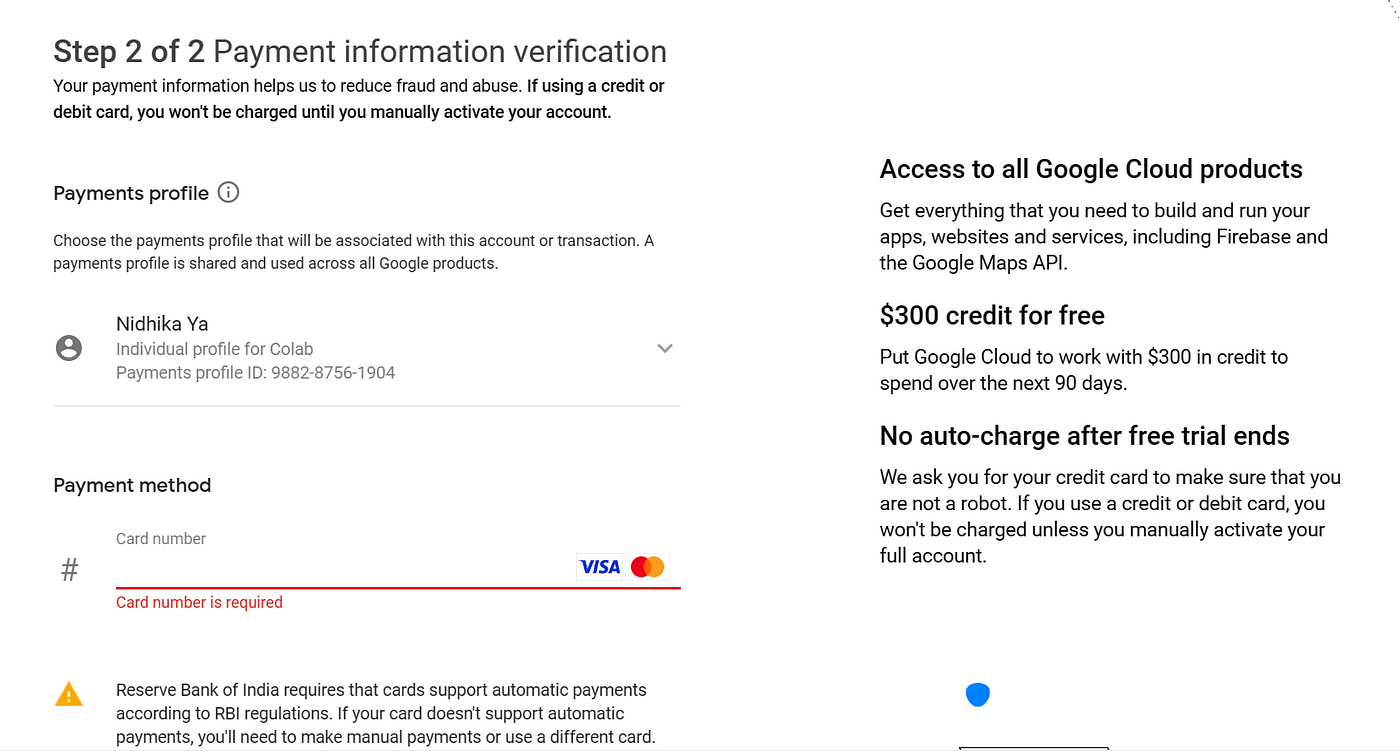
So, the point is-
What were the prompts given before the recordings in Gemini’s recordings or these one-liners were the only prompts?
— Which of the Gemini models was used to get these results?
— And can common men and women would be able to re-generate these outputs, with these given prompts?
— Does Bard really have Gemini by now?
Stay posted, subscribe on my blog. Here, https://nidhikayadav.org/
References
[2] Hands-on with Gemini: Interacting with multimodal AI (youtube.com)
[3] Google Bard: How to try the new Gemini AI model (blog.google)
[4] Google faces controversy over edited Gemini AI demo video (msn.com)
[5] Google admits it edited AI Gemini video as it chases OpenAI (afr.com)
[6] Introducing Gemini: Google’s most capable AI model yet (blog.google)
