Hi everyone, here is the link to my latest article which provides a prospective method for the task of Word Sense Disambiguation using the latest state-of-art developments in AI. My article is taken as it is from the following link in the original.
DOI: 10.13140/RG.2.2.15067.54567
Web Reference: (PDF) ChatGPT variant of Lesk Approach to Word Sense Disambiguation (researchgate.net)
Abstract: In this article, we explain how chatGPT can be used with the traditional Lesk WSD algorithm to technically improve the existing WSD methods. ChatGPT can be incorporated in other WSD algorithms as well. This article presents the idea and method behind using chatGPT with WSD and how chatGPT can be used for NLP and linguist analysis of WSD of a text fragment. No results on performance are presented in this article as it is not implemented but the reason to use ChatGPT with WSD with full descriptions and explanations are presented here.
Why we need Word Sense Disambiguation (WSD) when chatGPT is here now? And how to use chatGPT in latest state-of-art WSD algorithms. Here, in this article, we explain how chatGPT can be used with the traditional Lesk WSD algorithm. You can incorporate chatGPT in other WSD algorithms as well. This article presents the idea and method behind using chatGPT and how chatGPT can be used for NLP and linguist analysis of WSD of a text fragment. No results on performance are presented in this article as it is not implemented but the reason to use ChatGPT with WSD is presented here, further, we present here how to use chatGPT in WSD task, and the inception is shared in this article.
Let us see how chatGPT responds to a query on the polysemous word “bank”. Note if you need to code this article inception, you need to use the API of chatGPT as these results need to be fed into the WSD algorithm. The algorithm is explained at the end of the article.
Let’s first understand why chatGPT and how to use chatGPT!
Here is chatGPT response to: “Explain Bank”

So, there was no mention of bank by river side here. Let’s try a different query on chatGPT:
Here it goes:

Here, it mentions many meanings of banks and asks us to clarify what we need.
We need automated Word Sense Disambiguation. So, let us dive in a little more.
So, let us try the query: “Man on bank with an eye on fishes in river”. The following is the output of the query.

Here the chat engine can disambiguate the sense of the word bank. So, what was different in this, the difference was context. We provided the context more broadly to the chat engine and it responded correctly.
Now, how to check the accuracy over a wide variety of words that have multiple senses?
Well, there are a lot of datasets, and the chat engine must have tested their engine on these data sets in their research papers.
So, how do we do it?
We need a data set for it.
There are many datasets for Word Sense Disambiguation.
Some popular datasets are: semeval2013, other datasets are semeval2014, semeval2007, semeval2014, semeval2015, semeval2017,…
So why we are looking in semeval2013? As it has the word bank, this was the word we were discussing above, for having multiple meanings which need to be disambiguated. You can choose any ambiguous word.
Let us look in the file: semeval2013.gold.key
Search for the word bank in this file. Here are the search results:
- d004.s000.t000 bank%1:14:00::
- d004.s001.t001 bank%1:14:00::
- d004.s002.t002 bank%1:14:00::
- ….so on
Lets consider the first entry above viz.
“d004.s000.t000 bank%1:14:00::”
Now open the file: semeval2013.data.xml. In this file search the entry above that is “d004.s000.t000”
Here is the entry in this file:

This is the 4th document and first sentence in this document, this is the naming convention here. The sentence here is “US banks repay state support”
Let us do a search on chatGPT about this sentence: “US banks repay state support”
Here is the result from chatGPT:
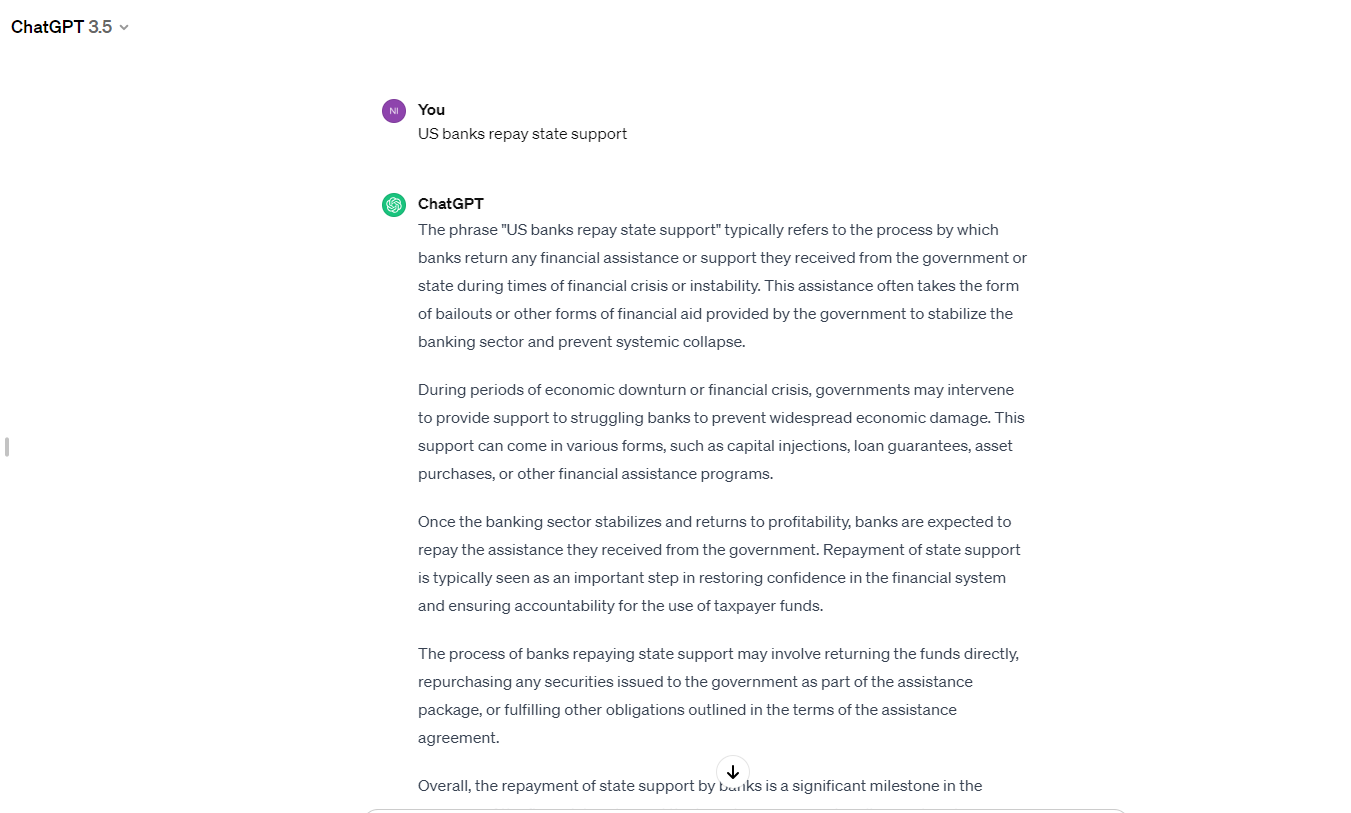
It clearly explains the financial banks now.
So, let us ask chatGPT what sense of word it refers to by querying it with the query term “word sense disambiguation of word “bank” in sentence “US banks repay state support””
Here it is:

So, chatGPT claims to be correct here. But how do we find the sense number?
Now look at wordnet sense online on wordnet API:
Here is what the search led to:
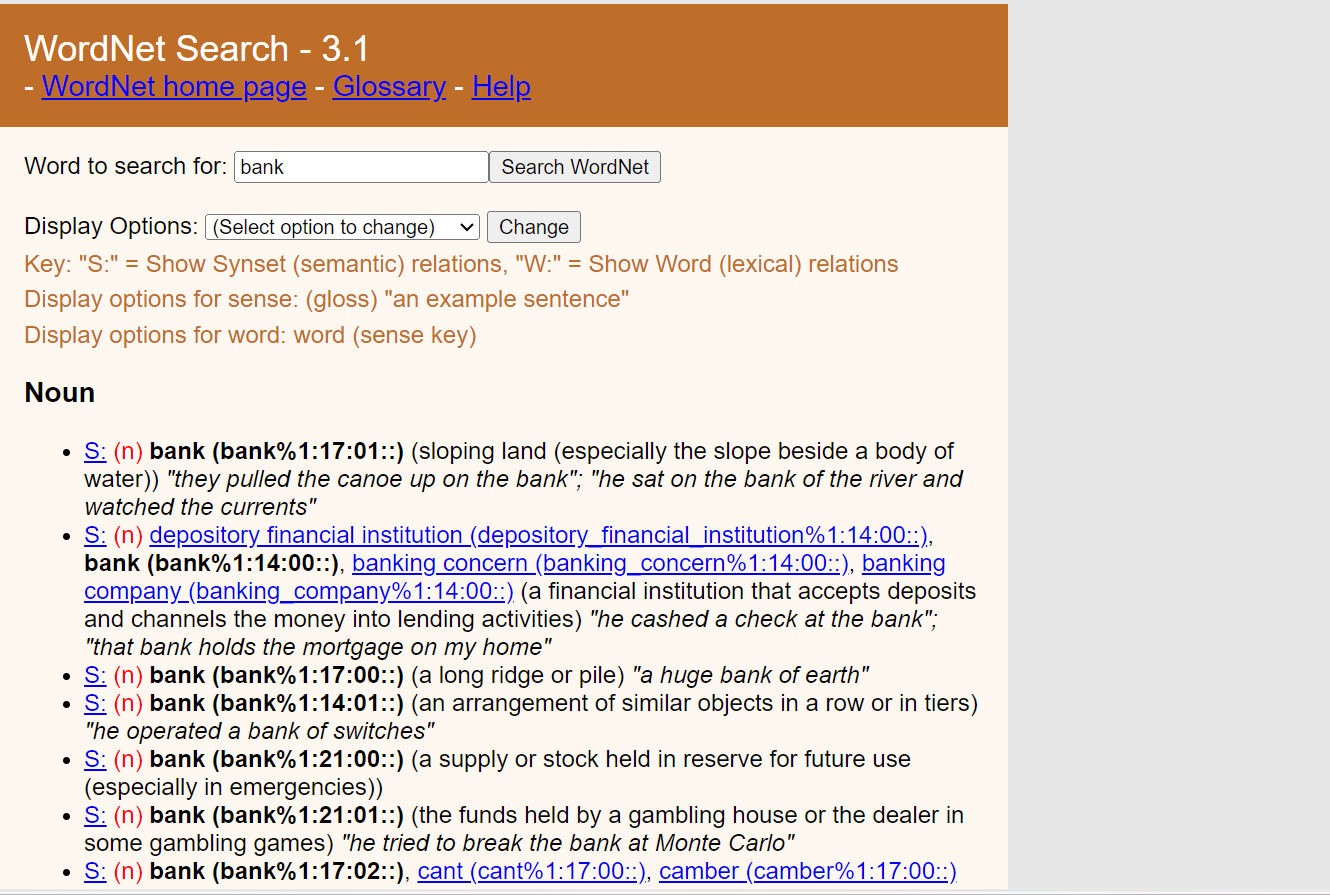

The gold solution means that the human-annotated output, as decided by human expert linguists. The gold solution is in the file semeval2013.gold.keyfor the above document and text taken above “d004.s000.t000”. This is for the sentence mentioned above: “US banks repay state support”
● S: (n) depository financial institution (depository_financial_institution%1:14:00::), bank (bank%1:14:00::), banking concern (banking_concern%1:14:00::), banking company (banking_company%1:14:00::) (a financial institution that accepts deposits and channels the money into lending activities) “he cashed a check at the bank”; “that bank holds the mortgage on my home”
This works well with chatGPT. So, has chatGPT solved the problem of Word Sense Disambiguation (WSD)?
Well not exactly, WSD task as seen above in Wordnet dictionary (as above in the screenshot). This shows that there are multiple senses of the word “bank” which also depends on the Part of Speech (POS) in which the word appears. So, the task of linguist and NLP researcher is not yet over once we receive the following output from chatGPT.

So, which sense from wordnet as described by linguists and NLP experts fit in here? That is still not clear, and NLP is a huge area where we need exact results.
Hence, here we propose an extension of Lesk Algorithm which uses chatGPT to produce the exact sense of the word. Here the algorithm is presented from the authors inception, readers are motivated to implement this as a research project.
Here are the details of how we can proceed to implement “ChatGPT variant of Lesk Approach to Word Sense Disambiguation”
But to users thinking what is this Lesk algorithm that we want to enhance with chatGPT. Here is the summary of Lesk Algorithm.
Lesk Algorithm:
-This is an unsupervised WSD algorithm.
-It disambiguates senses of the given word.
-It requires the context in which the word appears, typically the sentence where the word appeared or a fixed window size where the word appears, may be k word before and k words after the occurrence of the word.
-It needs WordNet Corpus to see the gloss of the word and to get all senses of the word.
Here is the Simple Lesk Algorithm:

Here, is the proposed chatGPT based Lesk Algorithm:

Here, chatGPT(c) is the API to query ChatGPT and is the description got from querying the context c, in which the word to be disambiguated is present. API can be used to expand the context so as to fasten the search results.
Other modification can be used to chatGPT(c), where in the context c can be modified to sentences like: “What is c?” and fed into API to query ChatGPT.
Further, the similarity can be computed by common words or any of the wordnet-based similarity methods.
This is it for the description of the method. This can be made a variant of other WSD algorithms as well. Now starts the implementation time.
