Hi All,
Hope you are doing well! I am on a journey to Australia so it takes me time to post technical articles these days.
Today in this article I describe one of my own research paper in layman language with the title “Fuzzy Rough Set Techniques for Extractive Text Summarization”. This was published in IETE Technical Review, 2019 — Taylor & Francis, as a part of my Ph.D. degree.
In this work, we developed techniques using Fuzzy Rough Set for extractive Text Summarization. No major such application has been performed before, the results were motivating for further research and enhancements. It has applications in many other NLP areas.
The basis of the work was the proposed sentence similarity using Fuzzy Rough Sets.
— It can be in coming future used in areas such as Information Retrieval, Recommender Systems, Query-based Summarization, and many other NLP applications such as Sentiment Analysis and Twitter Analytics, to mention a few.
You can go through the below-mentioned points and can intuitively come up with the application of Fuzzy Rough Set based sentence similarity in the NLP areas I proposed above. You can write to me in case you need help with any of these.
Key points in my paper Chatterjee & Yadav (2019) [1] in simple language are explained as follows:
— Fuzzy Rough Set (Komorowska et al, 1999) are designed for decision making with uncertainty and incompleteness.
— Text data does have some amount of uncertainty and incompleteness while representing it in form of data.
— The paper proposed Fuzzy Rough Set for the task of sentence similarity-based Text Summarization.
— The aim of the research was to formulate a way to use Fuzzy Rough sets to summarize text, so after reading past works in this area of Fuzzy Rough Sets we came to know that no such work exists and we delved into how to solve this problem. Then we came to an indirect application that has huge potential, using sentence similarity. Again there was no work on sentence similarity using Fuzzy Rough Sets, so we devised it ngth tuned using a universe containing only words as the objects of the universe as against typical data science work where objects of the universe are sentences or documents.
— These are knowledge-based methods.
— Further, we evaluated the effectiveness of Fuzzy Rough Set in computing similarity between two sentences.
— It has theoretical implications and can be used to analyze the theory of NLP with Fuzzy Rough Sets mathematically once explored in this direction with the model presented in this paper.
— Modeling the similarity between the sentences is performed here.
— Several models were generated using Fuzzy Rough Set for computing the similarity of two sentences.
— A novel technique using GLOVE (the then popular thing) and Fuzzy Rough Set was also used to compute the similarity between sentences apart from using models where WordNet was used to provide knowledge. Again this can be used for theoretical exploration of NLP tasks which can have practical implications.
— Experiments on sentence similarity were conducted on SICK2014 sentence similarity datasets.
— Mean square error and co-relation between actual sentence similarity score were computed.
— Next, we measure its effect on similarity-based summarization models.
— Evaluations using ROUGE scores were performed on DUC data sets for single document Text Summarization.
— We proposed to use Fuzzy Rough Sets for the task of sentence similarity-based Text Summarization.
— Two sentences may be equivalent in their meanings despite having different vector space representations.
— Fuzzy Rough Sets looks at the meaning of the sentences. It does not look at vector space representation that is the key point here.
— In the proposed model of Fuzzy Rough Sets a sentence S, is represented as a pair where lower approximation of the sentence and upper approximation of the sentence both of which are Fuzzy Sets using several techniques.
The following are definitions of Fuzzy lower and upper approximations this image is taken from my thesis as it is, rest all I wrote today.
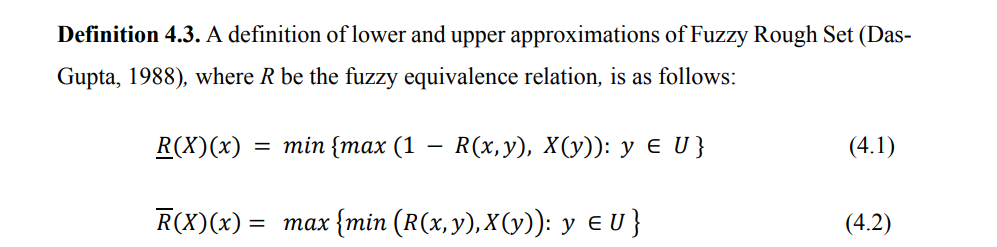
— We then devised a Fuzzy Rough Set based on lower similarity and a Fuzzy Rough Set based on upper similarities between two sentences using various ways.
— The lower similarity computed through several ways measures certainly similar content of two sentences using the two lower approximations of the two sentences, while upper similarity measures the degree of possibly similar content of the two sentences using the respective upper approximations of the two sentences.
— Knowledge in the form of lexical database of WordNet was used for computing the synonymy relation between the two words present in the Universe of words under consideration.
— The results obtained both for sentence similarity and for text summarization were motivating and paved the way to explore NLP mathematically.
Reference
[1] Chatterjee, N., & Yadav, N. (2019). Fuzzy rough set-based sentence similarity measure and its application to text summarization. IETE Technical Review, 36(5), 517–525.
