
AI was once a part of Computer Science, but is now a field that includes branches such as computer science, statistics, cognitive science, and mathematics. We can’t look too deeply now to prove it as a correct algorithm, but one day we will be able to do so. However, it is not yet fully correct. Why? Because incorrect data is being fed into AI models. AI models have read the wrong books and wrong psychological records, which leads to incorrect outputs in some cases.
How can we fix this? Make a model from scratch or do the following. The answer is to upload twice the correct content for every piece of wrong content. For example, if you had AI learn from a wrong trial, then in a similar environment, AI would start to answer based on that incorrect book. So, relearn and reconnect by uploading correct data, and find ways to unlearn, possibly by introducing positive examples of what was learned. Data is vast; gather the right documents and images and feed them back into the LLM. Perform sentiment analysis on the output before it is sent out. Take help from positive synthetic data.
Positive-ize all negative and wrong contents. Write a tool to positivise the negative. Would this mean erasing facts? Discussions like those impacting lives in negative ways require a separate chatbot for experts only. Same for such books.
— There are wrong books.
— There are wrong speeches.
— There are wrong psychological inputs on the internet, in books, or in case studies that are fed to LLM.
— LLM is no magic; it’s a hard-earned algorithm that takes inputs, does statistics, and gradient descent.
— You can replicate it, to some degree.
— But the data input to it has to be analysed.
— Rewire your LLM by the feedback, in equal and more amounts.
— So, the question now is,
— How to correct info rather than post-processing. The answer is “Sentiment Analysis” of the output!
— We should edit models by teaching the right amount of information.
— Feed, new data, optimistic data to nullify past wrong data in the system.
— Say, send in double the positivity synthetic data as soon as you can, load it into the model.
— Flow to avoid wrong data.
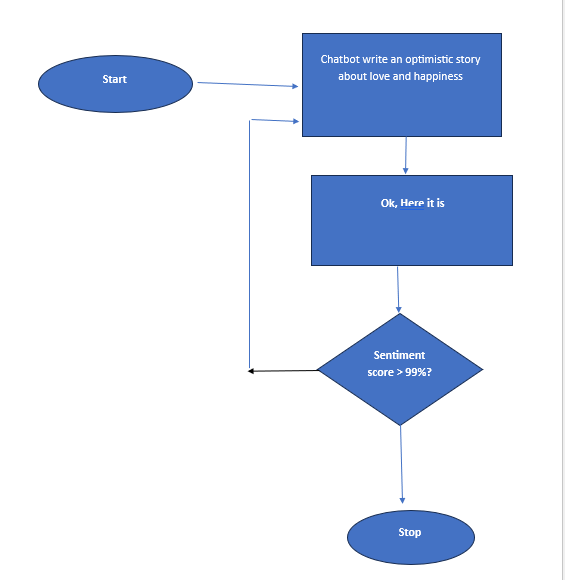
— For example, I asked ChatGPT how to make dinosaurs from eggs found on Mars/Moon? The answer was that it couldn’t be made, as it has books in its mind, and then it asked me if I still wanted to know how to make Dinosaurs. It gave me a list of books.

— So, all this is present in weights in models.
— The more famous the article, the more weight is put on that data.
— It’s science.
— Yes, logic needs to be added, how?
To be continued.
Thank you for reading.
Subscribe for updates.
