Let me illustrate this Python Project in depth once again.
AI: Sentiment Analysis and Fuzzy Sets based Summarization Technique — — Research based Approach (sample explanation with Python)
Here, in this article I am proposing a novel technique to summarize text documents. Well I am not writing a research paper for it but giving you basic explanations of key steps involved. It is a novel technique as sentiments have not been used with Fuzzy Inference Engine. I started working on this topic in 2016, though given time constraints and constraints, I didn’t publish the work yet. The work I did was in Java using Java based libraries. I have rewritten the code in Python for you to understand the basic steps, to be expanded into. Values and knowledge base in Fuzzy Inference Systems have to be edited as per applications. I have provided sample values for your understandings, not the values used in original research [which shall be send for publications and made available later].
This article can be taken as a (1) Tutorial for learning application of Fuzzy Inference Engine, Mamdani systems in particular, (2) Summarization technique in Python, (3) Novel research proposal for application of sentiment analysis in Fuzzy based Summarization Techniques.
Typically, this article was meant for research publication. But I have enough publications and I want research to reach humble minds for free! Here is the proposed technique in python.
1. Pre-processing documents and sentences
# import important NLP packages
from future import unicode_literals
import spacy,en_core_web_sm
from collections import Counter
nlp = spacy.load(‘en_core_web_sm’)
from spacy.matcher import Matcher
matcher = Matcher(nlp.vocab)
sentence_to_be_ranked = (‘Financially good conference situations.’)
text_document_snippet = (‘There is a developer beautiful and great conference happening on 21 July 2019 in London. The conference is in area of biological sciences.’)
#Load the complete document from a file. This is for illustration only
doc = nlp(text)
sent = nlp(title)
2. Get Largest Noun Chuck
Get the main longest noun chunk from the text fragment. Only most important chuck is being considered by the algorithm and shall be returned. There can be several kinds of chunking possible. Chunking is a kind of shallow processing. Why chucking — as it is useful in summarization techniques to highlight the important phrases. And largest chunks will be highlighted in the summary across all sentences after ranking them all. Other chunking techniques exists, look in my future articles about more on this. Here, just key steps of summarization.
# inputSentence is the input to of which the longest chunk is to be found
The indentation is lost because of pasting, I hope it can be understood by mature python writer
def getMainNounChuck(inputSentence):
lenChunk = 0
prevLen = -1
mainChunk = “”
for chunk in inputSentence.noun_chunks:
lenChunk = len(chunk)
print (chunk)
print(lenChunk)
if prevLen < lenChunk:
mainChunk = chunk
prevLen = lenChunk
print(“Main chunk is: “, mainChunk)
return mainChunk
Sample Output:
Main largest chunk in sentence for ranking is: Financially good conference situations
Main largest chunk in given 2 sentences is: beautiful and great conference
3. Get Sentiment Score of Sentence to be Ranked
There are several ways to compute the sentiment of a given sentence to be ranked as a part of collection of sentences to create an extract. The two methods are not exhaustive, but there are plethora of other options to compute the sentiments. For, research purposes I suggest you use a supervised or unsupervised trainer to train sentiment module on the topic of your interest, this means the domain in which you wish to perform the experiments: Is it sports news articles, medical articles, movie review summarization. Such a sentiment analyzer will be more beneficial to the output and relevance of results. But since the article aims to just give snippets of tasks in short. You can look on my other articles of how to learn sentiments per domain of text categories.
def getSentimentScore(doc):
print(“Sentiment is “, doc.sentiment * 10)
return doc.sentiment * 10
Another way to compute sentiment
def getsentiment2(sent):
from textblob import TextBlob
sentimentObject = TextBlob(sent)
sentimentObject = sentimentObject.sentiment
print(“Sentiment”, sentimentObject.polarity * 10)
return sentimentObject.polarity * 10
Sample Output:
sentence= (‘Financially good conference situations.’)
Sentiment 7.0
Preferable Recommended way which I use and suggest: A self trained model on corpus!
4. Similarity between document and sentence
The following small python code is enough to find basic similarity between a sentence and the text document(s) under consideration. Well there are several kinds of similarity measures in NLP some very popular being Wu-Palmer and Leacock Chordorow, path based similarity, Resnik measure, Lin measure to mention a few. As a researcher I suggest analysis on all these fronts before finalizing on any one. Some other similarity measures are lexical similarities, Cosine similarities among one-hot representations, vector space representations or FastText, GLOVE Vector representation or any other word embeddings such as Word2Vec or may be just WordNet based similarities. A lot of options to choose from. So which one I am using in this problem ? Or even in any other problem ? Still the task can be made more simple, the choice of algorithm…
def getSimilarity(sentence1, doc1):
return doc1.similarity( sentence1 )
Recommended: More insight in kind of similarity measure used esp. the most useful ones for a current problem. A deep insight is needed here, while choice of technique to be used is being made.
Sample Output:
The similarity between sentence and document is 0.3219
en_core_web_sm, don’t come with word vectors and utilizes surface level context-sensitive tensors. Hence for an efficient toolkit you would have to use more than this! I have implemented this fragment of work in Java using DL4J!
5. Get Part of Speech Count
Part of Speech is another parameter to the Fuzzy Inference Engine that I propose to use in a slightly different way. Being as in typical NLP summarization techniques using Fuzzy Inference Engines, an input is typically used as NOUN count. But here we have proposed to use: Noun Count, Adjective Count, Adverb Count to mention a few. The code snippet for a easy computation of count of a particular POS tag as specified in parameter “inputPOSTag” for text in “inputText” can be written in Python as follows.
def getPOSCOUNT(inputText, inputPOSTag):
nlp = en_core_web_sm.load()
count = 0
for tokenInputText in nlp(inputText):
countPOS +=1
dictonaryInputText= (Counter(([token.pos_ for token in nlp( tokenInputText)])))
print( dictonaryInputText )
return dictonaryInputText [inputPOSTag]/( countPOS+1) * 100
6. Checking Values-So far So Good
The following code is to check the values computed by the NLP Engine is fine or not ! If not change the algorithms and techniques used as suggested in points above. Once done go to next step of setting up Fuzzy Inference Engine for summarization.
print(getMainNounChuck(sent))
print(“the similarity between sentences is”, getSimilarity(nlp(title),getMainNounChuck(doc)))
getSentimentScore(sent)
print(“Noun count” , getPOSCOUNT(text,”NOUN”))
print(“Verb count”, getPOSCOUNT(text,”VERB”))
print(“Adj count”, getPOSCOUNT(text,”ADJ”))
Sample Output for input above.
Adjective count 11.53846
7. Defining Fuzzy Inference System (FIS) for Ranking Sentences
The following steps are performed for ranking the Fuzzy Inference System (FIS)
7.1. Defining the Antecedents and Consequents functions
The following input parameters are used. These are all defined above in the NLP Processing technique in details. Again this is a snippet for understanding, actual research has much more complex components, which are not discussed here in this article.
The Fuzzy Logic toolkits for illustration used are as follows:
import skfuzzy as fuzz
from skfuzzy import control as ctrl
The input parameters in FIS for the explanation are: [See skfuzzy for details on parameters and their detailed implications, which I am not explaining here. Given knowledge of Fuzzy Logic and Fuzzy Systems are assumed to be at considerable levels in this article]
similarity_document = ctrl.Antecedent(np.arange(0, 1.25, .1), ‘similarity’)
sentiment_score = ctrl.Antecedent(np.arange(0, 1.25, .1), ‘sentiment_score’)
nounCount = ctrl.Antecedent(np.arange(0, 110, 10), ‘nounCount’)
verbCount = ctrl.Antecedent(np.arange(0, 110, 10), ‘verbCount’)
adjCount = ctrl.Antecedent(np.arange(0, 110, 10), ‘adjCount’)
The following is the output variable defined with parameters as given below.
#consequent
rank = ctrl.Consequent(np.arange(0, 24, 1), ‘rank’)
7.2. Define the Input and Output Linguistic variables in FIS
The following is brief description of how to define the Fuzzy Sets involved in the process.
similarity[‘low’] = fuzz.trimf(similarity.universe, [0, 0.3, 0.5])
similarity[‘average’] = fuzz.trimf(similarity.universe, [0.3, 0.7, 1])
similarity[‘high’] = # define as per requirements in your problem
sentiment_score[‘low’] = fuzz.trimf(sentiment_score.universe, [0, 0.3, 0.5])
sentiment_score[‘average’] = fuzz.trimf(sentiment_score.universe, [0.3, 0.7, 1])
sentiment_score[‘high’] = # define as per requirements in your problem
nounCount[‘low’] = fuzz.trimf(nounCount.universe, [0, 30, 50])
nounCount[‘average’] = fuzz.trimf(nounCount.universe, [30, 70, 100])
nounCount[‘high’] = # define as per requirements in your problem
verbCount[‘low’] = # define as per requirements in your problem
verbCount[‘average’] = # define as per requirements in your problem
verbCount[‘high’] = # define as per requirements in your problem
adjCount[‘low’] = # define as per requirements in your problem
adjCount[‘average’] = # define as per requirements in your problem
adjCount[‘high’] = # define as per requirements in your problem
Pictorial Representation of some Fuzzy sets defined for illustration (sentiment_score):
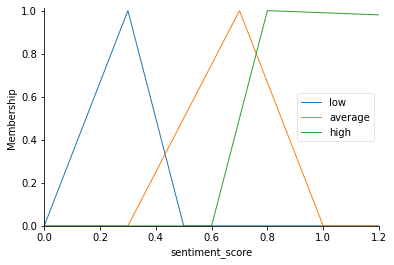
7.3 Output Membership Functions for Linguistic Variable Rank
rank[‘low’] = fuzz.trimf(rank.universe, [0, 0, 10])
rank[‘average’] = # define as per requirements in your problem
rank[‘high’] = # define as per requirements in your problem
Sample Fuzzy Sets for “rank”
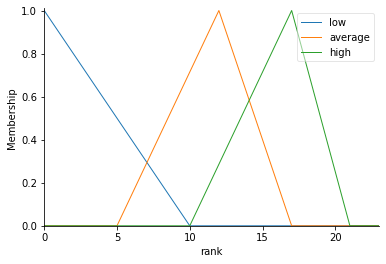
7.4 View the Fuzzy Sets
sentiment_score.view()
nounCount.view()
verbCount.view()
adjCount.view()
similarity.view()
rank.view()
8. FIS Rulebase-Sample
The following are some sample rules for FIS summarization toolkit. These are not exhaustive and are documented here to illustrate the procedure and to pave your understandings.
rule1 = ctrl.Rule(similarity[‘low’] | sentiment_score[‘low’], rank[‘low’])
rule2 = ctrl.Rule(sentiment_score[‘average’], rank[‘average’])
rule3 = ctrl.Rule(sentiment_score[‘average’] | similarity_title[‘average’], rank[‘average’])
rule4 = # define as per requirements and experts views
rule5 = # define as per requirements and experts views
rule6 = # define as per requirements and experts views
rule7 = # define as per requirements and experts views
rule8 = # define as per requirements and experts views
rule9 = # define as per requirements and experts views
rule10 = ctrl.Rule(similarity[‘high’] & nounCount[“high”] & sentiment_score[‘high’] & verbCount[“high”] , rank[‘high’])
Define FIS system now and perform simulations.
rankFIS = ctrl.ControlSystem([rule1, rule2, rule3, rule4, rule5, rule6, rule7, rule8, rule9, rule10])
rankFIS = ctrl.ControlSystemSimulation(rankFIS)
9. Computing Rank (Importance) of a Sentence using the sample FIS
Here for a particular a sentence whose importance or rank in respect to other members of text fragments is to be computed. The NLP properties defined in 2–6 above are computed and set in the FIS system as below:
rankFIS.input[‘similarity_title’] = getSimilarity(doc,sent)
rankFIS.input[‘sentiment_score’] = getsentiment2( sent )
rankFIS.input[‘nounCount’] = getPOSCOUNT( sentNLP ,”NOUN”)
rankFIS.input[‘verbCount’] = getPOSCOUNT( sentNLP ,”VERB”)
rankFIS.input[‘adjCount’] = getPOSCOUNT( sentNLP ,”ADJ”)
The following steps illustrates computation of ranks based on the inputs just provided through computations above.
rankFIS.compute()
print (“the answer is”)
print (rankFIS.output[‘rank’])
#view the Fuzzy Inference System
rank.view(sim=rankFIS)
The output of illustrative FIS for input taken in this article is as follows:
Rank = 7.3040, The FIS Rank defuzzification is as follows:
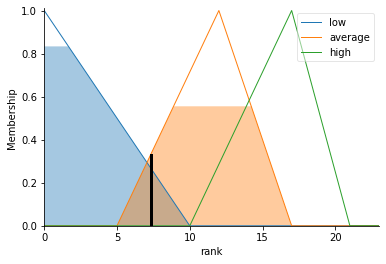
10. Conclusions
This was a brief article explaining the key steps in building FIS based system for summarization. Once ranks for all sentences are formed the main chunk identified in top p% of sentences can be highlighted in the application as the output of the tool. This is a novel approach in that sentiments have not been used in any work with FIS for summarization as of now. Also adjective count, chunking, adverb counts have not been used prior to this proposal in this article.
The aim of article is to lay emphasis that research can progress outside research publications too ! At least research proposals can ! Further this article explains how to use FIS in NLP application of text extraction.
