Here is a code for sentiment analysis explained with sentiwordnet. The code is here for determining the sentiment analysis of a sentence.
I have used this on the climate dataset with me. And found the most positive sentiment-oriented documents and most negatively oriented documents, also the most lengthy documents too.
Here is a simple code of sentiment analysis using sentiWordNet.
Initialization as follows:
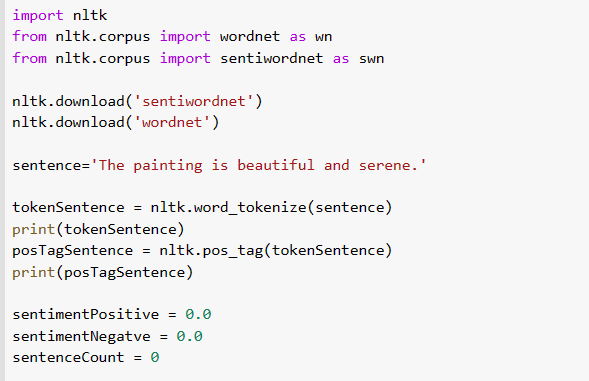
Now, use the sentiwordnet package and find sentiments.

…
This returns the positive and negative scores of the sentence.
The output is as follows:

…
The full code is here:
import nltk
from nltk.corpus import wordnet as wn
from nltk.corpus import sentiwordnet as swn
nltk.download('sentiwordnet')
nltk.download('wordnet')
sentence='The painting is beautiful and serene.'
tokenSentence = nltk.word_tokenize(sentence)
print(tokenSentence)
posTagSentence = nltk.pos_tag(tokenSentence)
print(posTagSentence)
sentimentPositive = 0.0
sentimentNegatve = 0.0
sentenceCount = 0
for wordTagPair in posTagSentence:
word = wordTagPair[0]
posTag = wordTagPair[1]
print(word, posTag)
if posTag.startswith('J'):
posTag = wn.ADJ
elif posTag.startswith('R'):
posTag = wn.ADV
elif posTag.startswith('N'):
posTag = wn.NOUN
else:
continue
wordSynst = wn.synsets(word, pos=posTag)
if not wordSynst:
continue
chosenSynst = wordSynst[0]
sentiWordNet = swn.senti_synset(chosenSynst.name())
print(sentiWordNet)
sentimentPositive += sentiWordNet.pos_score()
sentimentNegatve += sentiWordNet.neg_score()
sentenceCount += 1
print('The positive and negative sentiments of given sentence are: ')
print (sentimentPositive, sentimentNegatve)
