#AI
In this article, a research-based approach to solving information retrieval of Climate Documents is provided.
Several places suggestions are provided for what can be done to improve the work.
This is an AI Exercise and can be enhanced to be a full project with minor-major changes and workouts. This has been explained in python.
Here, the code starts
pip install nltk
nltk.download('all')
Rest pre-processing the files as in my previous articles. This part is skipped as has been covered in prior writings.
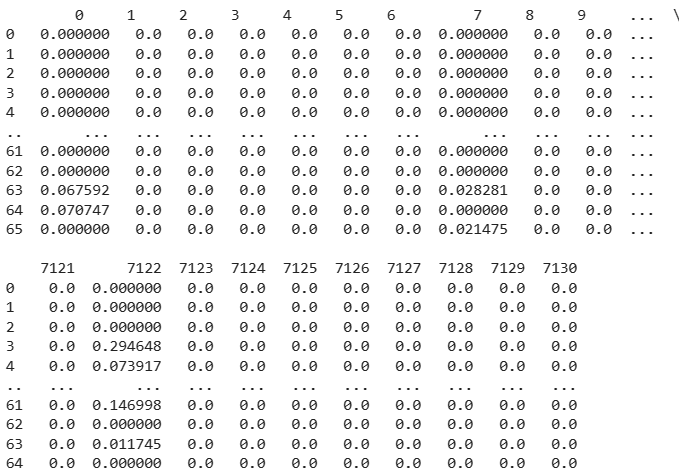
Here, compute the tf-idf vectors for each file in dataset. The dataset has 66 files from the climate dataset.
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
#read the documents
vecTfidf = TfidfVectorizer(analyzer='word',stop_words= 'english')
tf_idf = vecTfidf.fit_transform(docs_vector)
tfidf_features = vecTfidf.get_feature_names()
tf_idfArray = pd.DataFrame(tf_idf.toarray())
print(pd.DataFrame( tf_idfArray))
print(tfidf_features)
The output looks like:
Compute dot product with the query:
import numpy as np
from numpy.linalg import norm
def cosinesim(array1, array2):
# compute cosine similarity
cosine = np.dot(array1,array2)/(norm(array1)*norm(array2))
return cosine
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
queryText = ["No country today is immune from the impacts of climate change."]
queryVectorArray = queryVector.toarray()
test_document = np.array([tf_idfArray[1]])
one_d_Array = queryVectorArray[0]
maxLoc = 0
cos_Sim_Query = []
for i in range(66):
array_tfidf_ = (tf_idf[i]).toarray()
cos_Sim_Query.append( cosinesim(array_tfidf_, one_d_Array)[0])
Inputs of Fuzzy System are:
- Similarity of query to document
- Sentiment score of the document
Output of Fuzzy System is:
- Ranking of documents, here rank from 1 to 10 is allocated
From this rank, output is generates.
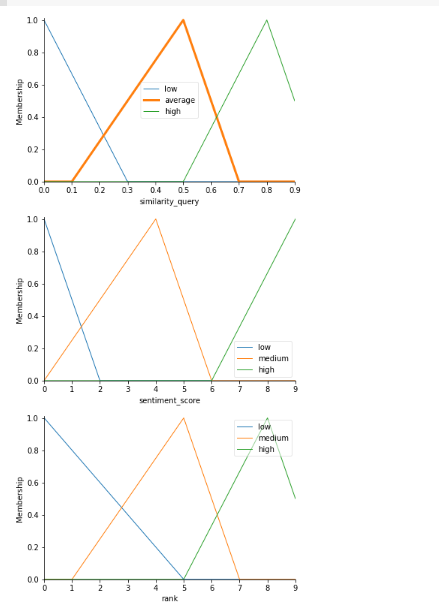
These are all Fuzzy linguistic variables and they are defined as below.
The Fuzzy Inference Engine is described for the problem as follows:
import numpy as np
import skfuzzy as fuzz
from skfuzzy import control as ctrl
# Antecedent/Consequents functions
similarity_query = ctrl.Antecedent(np.arange(0, 1, .1), 'similarity_query')
sentiment_score = ctrl.Antecedent(np.arange(0, 10, 1), 'sentiment_score')
rank = ctrl.Consequent(np.arange(0, 10, 1), 'rank')
similarity_query['low'] = fuzz.trimf(similarity_query.universe, [0, 0, 0.3])
similarity_query['average'] = fuzz.trimf(similarity_query.universe, [0.1, 0.5, 0.7])
similarity_query['high'] = fuzz.trimf(similarity_query.universe, [0.5, 0.8, 1])
sentiment_score['low'] = fuzz.trimf(sentiment_score.universe, [0, 0, 2])
sentiment_score['medium'] = fuzz.trimf(sentiment_score.universe, [0 , 4, 6])
sentiment_score['high'] = fuzz.trimf(sentiment_score.universe, [6, 9, 10])
rank['low'] = fuzz.trimf(rank.universe, [0, 0, 5])
rank['medium'] = fuzz.trimf(rank.universe, [1, 5, 7])
rank['high'] = fuzz.trimf(rank.universe, [5, 8, 10])
similarity_query['average'].view()
sentiment_score.view()
rank.view()
rule1 = ctrl.Rule(similarity_query['low'] | sentiment_score['low'], rank['low'])
rule2 = ctrl.Rule(similarity_query['average'] | sentiment_score['medium'], rank['medium'])
rule3 = ctrl.Rule(sentiment_score['high'] | similarity_query['high'], rank['high'])
rule4 = ctrl.Rule(similarity_query['high'] & sentiment_score['low'], rank['medium'])
rule5 = ctrl.Rule(similarity_query['high'] & sentiment_score['medium'], rank['medium'])
rule6 = ctrl.Rule(similarity_query['average'] & sentiment_score['low'], rank['medium'])
rule6 = ctrl.Rule(similarity_query['average'] & sentiment_score['low'], rank['medium'])
rule7 = ctrl.Rule(similarity_query['high'] & sentiment_score['low'], rank['high'])
rule8 = ctrl.Rule(similarity_query['low'] & sentiment_score['high'], rank['high'])
rule9 = ctrl.Rule(similarity_query['low'] & sentiment_score['medium'], rank['medium'])
rule10 = ctrl.Rule(similarity_query['low'] & sentiment_score['low'], rank['low'])
rule1.view()
rankFIS = ctrl.ControlSystem([rule1, rule2, rule3, rule4, rule5, rule6, rule7, rule8, rule9, rule10])
rankFIS = ctrl.ControlSystemSimulation(rankFIS)
The memberships are defined as follows:
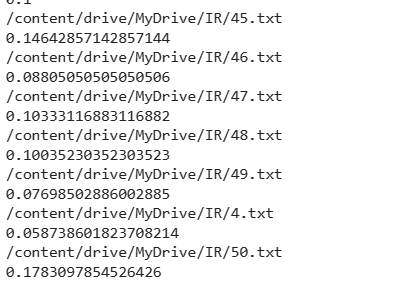
Compute the sentiments of each document and store the values per document in an array
from textblob import TextBlob
fileNames = []
docs_vector = []
sentiment_doc= []
for file in document_text:
fileNames.append(file)
docs_vector.append(document_text[file])
sentimentObj = TextBlob(document_text[file])
print(file)
print(sentimentObj.sentiment.polarity)
sentiment_doc.append(sentimentObj.sentiment.polarity)
Sample output:
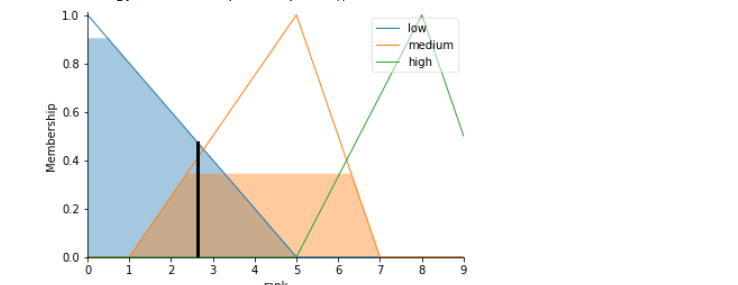
Computing the rank from Fuzzy Inference Engine
rankFIS_Results = []
for i in range(66):
rankFIS.input['similarity_query'] = cos_Sim_Query[i]
rankFIS.input['sentiment_score'] = sentiment_doc[i]
rankFIS.compute()
print ("the answer is")
print(rankFIS.output['rank'])
rank.view(sim=rankFIS)
rankFIS_Results.append(rankFIS.output['rank'])
Generating the information retrieval results:
Ranked Documents in outputs are as follows:
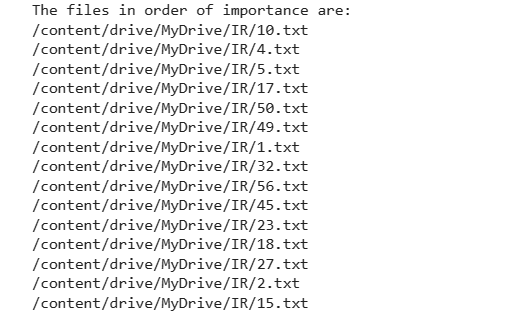
Suggestions
- The Fuzzy Inference Engine needs to be self-learning from the dataset.
- More combinations of Fuzzy Inference System memberships need to be tried.
- The sentiment engine needs to be more elaborate in the computations of sentiments.
- Rules need to be computed in more extensive way in which more testing can be done.
- Rules can be learned automatically from data.
- More inputs can be included in this technique.
- Other ways to represent documents can be considered. Other than tf-idf.
