Here in this short article, we analyze Information Retrieval of documents using tf-idf technique. Though this technique is not that popular, but it for sure in parts is backbone of many algorithms. Now, with deep learning this technique has been sidelined, but, none the less, it is the key session of Information Retrieval research. The code written here is in python and the data is climate data.
Let’s start.
Information Retrieval deals with retrieving and ranking documents which are important to a query. So, given a query — which are most important documents? This is the question an information retrieval engine answers. And rank the documents as per the importance levels.
document_text is a dictionary here with document names as
index and document content as a value.
fileNames = []
docs_vector = []
for file in document_text:
fileNames.append(file)
docs_vector.append(document_text[file])
print(docs_vector)
Now, the document_text[file] has the content of this file named file here.
Let us use the inbuilt tf-idf vectorizer from sklearn. Here, it is.
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
#read the document files
vecTfidf = TfidfVectorizer(analyzer='word',stop_words= 'english')
tf_idf = vecTfidf.fit_transform(docs_vector)
tfidf_features = vecTfidf.get_feature_names()
tf_idfArray = pd.DataFrame(tf_idf.toarray())
print(pd.DataFrame(tf_idfArray))
print(tfidf_features)
The run of this code leads to:
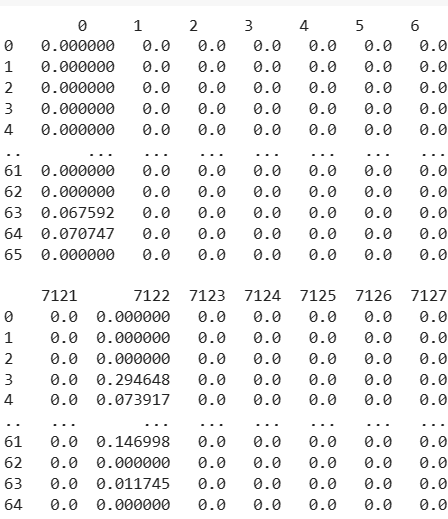
The above are representation of the documents in terms of word vectors. This can be seen are word vector representations.
Let the query be:
queryText = ["No country today is immune from the impacts of climate change."]
One nice way to find similarity between two documents or a document and a query is as follows, using cosine similarity between the vector representation of two entities, documents and/or query. The cosine similarity is coded as:
import numpy as np
from numpy.linalg import norm
def cosinesim(array1, array2):
# compute cosine similarity
cosine = np.dot(array1,array2)/(norm(array1)*norm(array2))
print("Cosine Similarity:", cosine)
return cosine
Query need to be represented in same format as the rest of the documents and hence transform method suits best to represent the query.
The query may be in sparse format and need to be expanded. Here is how to do it.
queryVectorArray = queryVector.toarray()
one_d_Array = queryVectorArray[0]
You can also process the query in transform with documents but that ends the very topic of transform later.
Let one_d_Array be the transform of the query in this word vector representation then we can find similarity of documents and the transform of query vector as follow:
import numpy
maxLoc = 0
cos_Sim_Query = []
for i in range(66):
array_tfidf_ = (tf_idf[i]).toarray()
cos_Sim_Query.append( cosinesim(array_tfidf_, one_d_Array)[0])
sort_index = numpy.argsort(cos_Sim_Query)
print('sorted files are')
print(sort_index)
print("The files in order of importance are: ")
for i in range(66):
print(fileNames[sort_index[65-i]])
tf_idf is as defined above on top of the page is a representation of ith document in the transformed space.
The output is as follows:
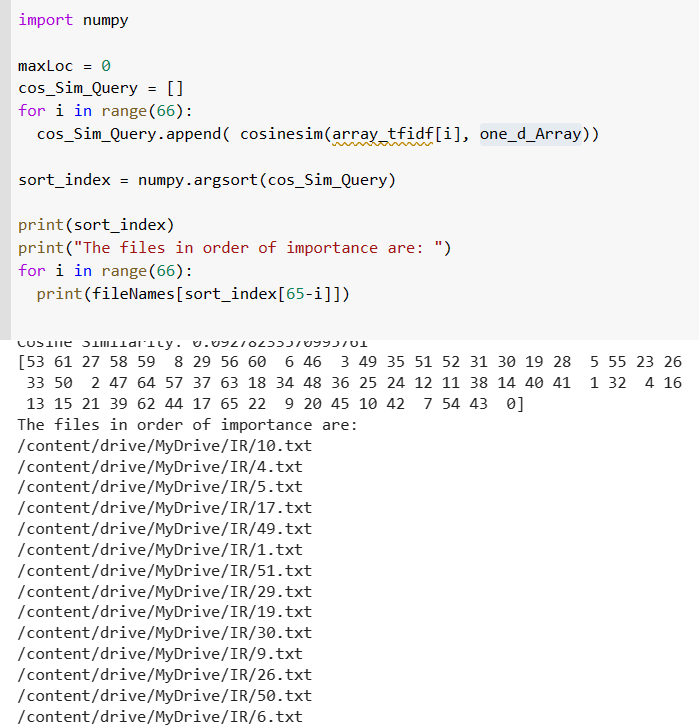
So here, for our query “No country today is immune from the impacts of climate change.” the best document was document 10, and indeed it is true as well. Next important document is 4 and 5 and so on.
This ends the application
