In this article, we shall see how climate text data collected and computed for analysis in previous articles can be analyzed for sentiment analysis.
The toolkit used today for text sentiment analysis is TextBlob. There are several other ways to compute sentiments. But the steps shall be the same though the libraries can change. Lets us focus on TextBlob for sentiment analysis of text in this article.
The steps to do sentiment analysis is as follows:
- Pre-preprocess the climate data in text format.
- Get keywords which are similar the main words. This is because we want to analyze the sentiments. The complete data set is huge with more than 60000 non-stop words. So let’s take keywords which are similar to words such as climate, weather, and so on and do sentiment evaluations on them.
- Get the highest frequency words. We shall also look at the highest frequency words for their sentiment opinion on the entire corpus.
- This is it for today. This ends with conclusions.
Step 1: Pre-Process
Here is the code block for basics text extractions
import gensim
from gensim.models import Word2Vec
from nltk.tokenize import sent_tokenize, word_tokenize
textTrainingInput = []
climateFolder = open("/content/fileList.txt")
climateFile = climateFolder.readlines()
stopwords = nltk.corpus.stopwords.words("english")
def readfiles(climateFile):
numSentences = 0
numWords = 0
numWords_nonStopWords = 0
wordList = []
dict_file_details_sentences = {}
allSentences = []
for climateFileName in climateFile:
fullFileName = "/content/drive/MyDrive/IR/" + climateFileName
fileNameObj = open(fullFileName)
sentencesInTraining = fileNameObj.read()
for sentence in sent_tokenize(sentencesInTraining):
numSentences +=1
allSentences.append(sentence)
for word in word_tokenize(sentence):
numWords += 1
........................................
The aim is to make a vector of sentences in the whole corpus. The rest part of code is computational. The key steps which are related to today’s article are given here.
Output of above code also gives the statistics of corpus
Statistics of Corpus:
Number of total sentences: 3639
Number of words: 97099
Number of non stop words: 66255
Step 2: Keywords near “climate”
Let’s do word2vec object generation with the input as obtained in step 1 above. This we will do with the neural model of word2vec that we generated.
model_bow = gensim.models.Word2Vec(textTrainingInput, window = 5)
Let us find top 20 similar words to word “climate”
similar_words = model_bow.wv.most_similar("climate", topn=20)
for w in similar_words:
print(w)
Here is the output

Similarly, we can do it for word “storm”
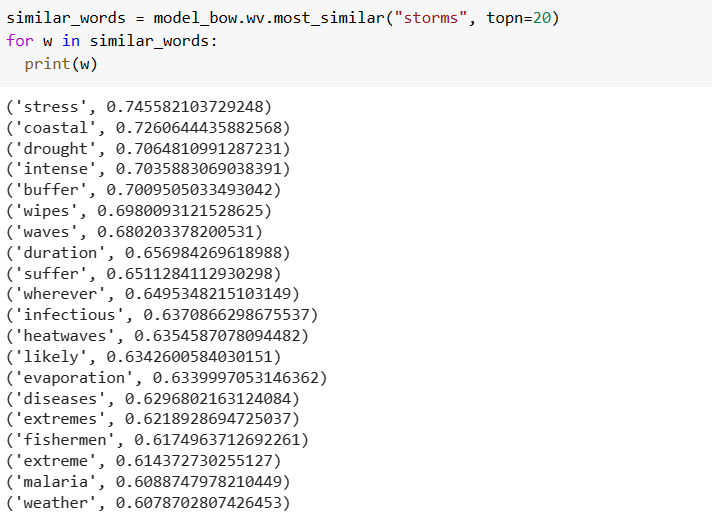
Now, lets do it for word “weather”
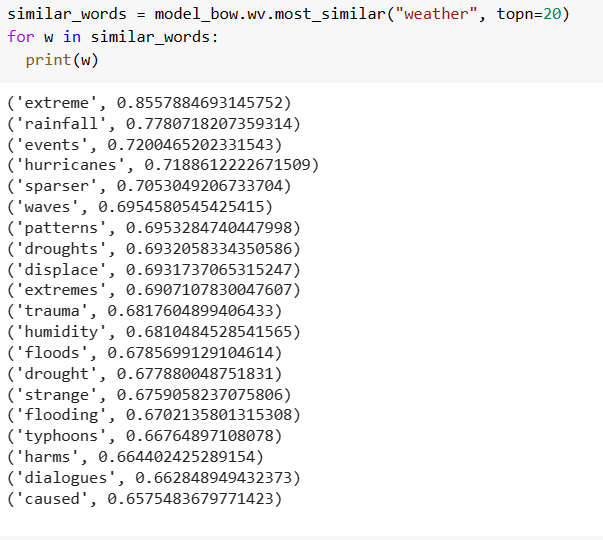
We can see the words generated are highly related to the query word.
similar_words = model_bow.wv.most_similar("climate", topn=20)
for w in similar_words:
print(w)
max = 0
i = 0
index = 0
for w in similar_words:
similarity = model_bow.wv.similarity("climate", w[0])
if max <= similarity:
max = similarity
index = i
print("similarity between: ", w[0], " and ", "climate", " is ", similarity)
i = i + 1
print("Maximum Orietation Towards", similar_words[index][0], " " , max)
The output is as follows:
similarity between: consequences and climate is 0.44554597
similarity between: driven and climate is 0.44036892
similarity between: positive and climate is 0.43950814
similarity between: ground-breaking and climate is 0.43335918
similarity between: change and climate is 0.42466486
similarity between: disastrous and climate is 0.42079106
similarity between: discourse and climate is 0.41835168
similarity between: humans and climate is 0.40202492
similarity between: emergency and climate is 0.39848965
similarity between: negative and climate is 0.39407492
similarity between: signals and climate is 0.3900744
similarity between: result and climate is 0.3890312
similarity between: vulnerable and climate is 0.38664946
similarity between: prompting and climate is 0.37466392
similarity between: effects and climate is 0.37307057
similarity between: depending and climate is 0.37236375
similarity between: climatic and climate is 0.36538297
similarity between: looks and climate is 0.35855216
similarity between: ambition and climate is 0.35804877
Maximum Orietation Towards consequences 0.44554597
The maximum similarity word here is “consequences”
Let’s start sentiment analysis now,
The first step is to install textblob
!pip install textblob
Now, I have made the following two methods:
- The first, is to get the sentence form corpus which have a particular keyword. This sentence has the first occurrence of word called findword.
Here, the words are those words that are near to the word climate, as found above.
def findSentenceWithWord(findword):
for sent in allSentences:
if(sent.find(findword)>0):
return sent
return 0
2. This method finds all sentences in corpus that have the specific word keyword
#all sentence having this word
def findAllSentenceWithWord(findword):
outputSentences = ""
numSent = 0
for sent in allSentences:
if(sent.find(findword)>0):
numSent += 1
outputSentences = outputSentences+ " " + sent
return outputSentences, numSent
findSentenceWithWord
Sentiment Analysis on all words similar to word climate or any other important keyword. First with only one sentence containing the word from corpus. This is as follows:
similar_words = model_bow.wv.most_similar("climate", topn=20)
max = 0
i = 0
index = 0
total_Sentiment = 0
for w in similar_words:
sentenceWord = findSentenceWithWord(w[0])
sentimentObj = TextBlob(sentenceWord)
sentiment_w = sentimentObj.sentiment.polarity
total_Sentiment += sentiment_w
if max <= sentiment_w:
max = sentiment_w
index = i
print("Sentiment of ", w[0], " in climate data", " is ", sentiment_w)
#print("Sentence is", sentenceWord)
i = i + 1
print( "Total sentiment is", total_Sentiment )
print( "Average total sentiment is", total_Sentiment/len(similar_words) )
print("Maximum sentiment word is", similar_words[index][0] )
Output is as follows:
Sentiment of consequences in climate data is 0.3
Sentiment of driven in climate data is 0.5
Sentiment of positive in climate data is -0.1
Sentiment of ground-breaking in climate data is 0.16142857142857142
Sentiment of change in climate data is 0.0
Sentiment of disastrous in climate data is 0.10000000000000003
Sentiment of discourse in climate data is -0.325
Sentiment of humans in climate data is -0.038095238095238106
Sentiment of emergency in climate data is 0.0
Sentiment of negative in climate data is -0.3
Sentiment of signals in climate data is 0.17272727272727273
Sentiment of result in climate data is -0.026666666666666672
Sentiment of vulnerable in climate data is -0.06799999999999999
Sentiment of prompting in climate data is 0.075
Sentiment of effects in climate data is -0.125
Sentiment of depending in climate data is 0.0
Sentiment of climatic in climate data is -0.06666666666666667
Sentiment of looks in climate data is 0.1
Sentiment of ambition in climate data is 0.0
Total sentiment is 0.4349373567608864
Average total sentiment is 0.02174686783804432
Maximum sentiment word is driven
Same analysis can be done on other keywords as well.
similar_words = model_bow.wv.most_similar(“weather”, topn=20)

Leaving the rest exercises to readers, it’s similar to the above analysis. I hope you ll be able to do it.
findAllSentenceWithWord
Sentiment Analysis on all words similar to word climate. Here, with all the sentences containing the word from the corpus. This is as follows:
similar_words = model_bow.wv.most_similar("climate", topn=20)
max = 0
i = 0
index = 0
total_Sentiment = 0
for w in similar_words:
sentenceWord, numSent = findAllSentenceWithWord(w[0])
sentimentObj = TextBlob(sentenceWord)
sentiment_w = sentimentObj.sentiment.polarity
total_Sentiment += sentiment_w
if max <= sentiment_w:
max = sentiment_w
index = i
print("Sentiment of ", w[0], " in climate data", " is ", sentiment_w)
i = i + 1
print( "Total sentiment in all sentences: ", total_Sentiment)
print( "Average sentiment is", total_Sentiment/len(similar_words) )
print("Maximum sentiment word is", similar_words[index][0] )
The output is as follows:
Sentiment of consequences in climate data is 0.033454106280193255
Sentiment of driven in climate data is 0.09736842105263158
Sentiment of positive in climate data is 0.09845218595218586
Sentiment of ground-breaking in climate data is 0.16142857142857142
Sentiment of change in climate data is 0.06950319754520297
Sentiment of disastrous in climate data is -0.032142857142857126
Sentiment of discourse in climate data is -0.325
Sentiment of humans in climate data is 0.06173369641111576
Sentiment of emergency in climate data is 0.07421052631578946
Sentiment of negative in climate data is -0.09500811688311686
Sentiment of signals in climate data is 0.14991883116883115
Sentiment of result in climate data is 0.05352891156462586
Sentiment of vulnerable in climate data is -0.021992152666309973
Sentiment of prompting in climate data is 0.075
Sentiment of effects in climate data is 0.046157460682777145
Sentiment of depending in climate data is 0.09682539682539681
Sentiment of climatic in climate data is -0.03703703703703704
Sentiment of looks in climate data is 0.009920634920634917
Sentiment of ambition in climate data is 0.13150411255411254
Total sentiment in all sentences: 0.7417132516101103
Average sentiment is 0.03708566258050551
Step 3: Pre-Process highest Frequency words for sentiment analysis
Find the highest frequency terms in data, as follows
# Compute the frequencies of words
print(wordList[1])
wordsFiltered = wordList
wordsFiltered = [w for w in wordsFiltered if not(isSpecialCharacter(w))]
wordsFiltered = [w for w in wordsFiltered if w.lower() not in stopwords]
wordsFiltered = [w.lower() for w in wordsFiltered]
dict_word_freq = {}
for word in wordsFiltered:
if (word in dict_word_freq):
dict_word_freq[word] += 1
else:
dict_word_freq[word] = 1
print(dict_word_freq)
for key, value in dict_word_freq.items():
print ("% s : % d"%(key, value))
Use the following toolkit to get top N words
from heapq import nlargest
def getTopNwords(N):
print("The original dictionary is : " + str(dict_word_freq))
top_N = nlargest(N, dict_word_freq, key = dict_word_freq.get)
print("The top N value pairs are ")
return top_N
import numpy as np
import matplotlib.pyplot as plt
top_dict_word_freq = {}
topNwords =getTopNwords(25)
for word in topNwords:
top_dict_word_freq[word] = dict_word_freq.get(word)
topwords = list(top_dict_word_freq.keys())
frequencies = list(top_dict_word_freq.values())
Top Frequency Words Sentiment Analysis
- Here with the first sentence of occurance of a keyword form corpus
highest_freq_words = list(top_dict_word_freq.keys())
max = 0
i = 0
index = 0
total_Sentiment = 0
for w in highest_freq_words:
sentenceWord = findSentenceWithWord(w[0])
sentimentObj = TextBlob(sentenceWord)
sentiment_w = sentimentObj.sentiment.polarity
total_Sentiment += sentiment_w
if max <= sentiment_w:
max = sentiment_w
index = i
print("Sentiment of ", w, " in climate data", " is ", sentiment_w)
i = i + 1
print( "Total sentiment in all sentences: ", total_Sentiment)
print( "Average sentiment is", total_Sentiment/len(similar_words) )
print("Maximum sentiment word is", highest_freq_words[index] )
The output is
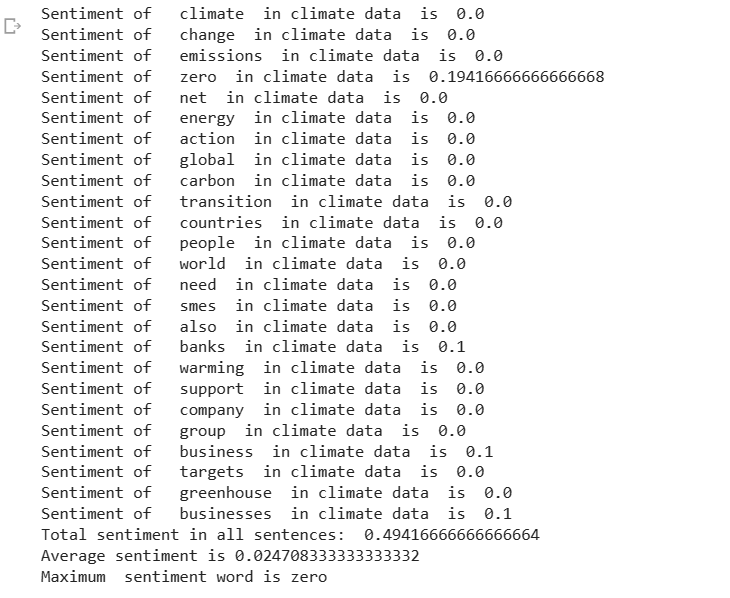
2. Here all sentences with the occurrence of the keyword from top frequencies
highest_freq_words = list(top_dict_word_freq.keys())
max = 0
i = 0
index = 0
total_Sentiment = 0
for w in highest_freq_words:
sentenceWord, numSent = findAllSentenceWithWord(w[0])
sentimentObj = TextBlob(sentenceWord)
sentiment_w = sentimentObj.sentiment.polarity
total_Sentiment += sentiment_w
if max <= sentiment_w:
max = sentiment_w
index = i
print("Sentiment of ", w, " in climate data", " is ", sentiment_w)
i = i + 1
print( "Total sentiment in all sentences: ", total_Sentiment)
print( "Average sentiment is", total_Sentiment/len(similar_words) )
print("Maximum sentiment word is", highest_freq_words[index] )
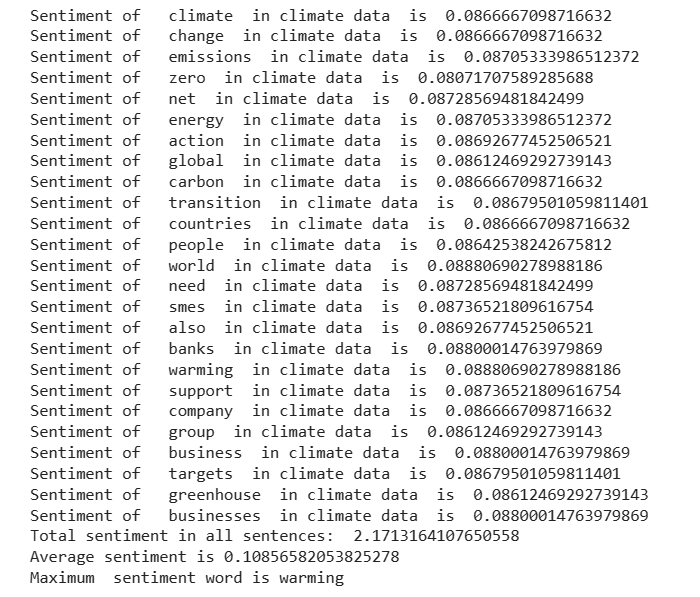
Step 4: Conclusion
The same can be done with other words in climate data as well such as storm, weather, and so on. The sentiment knowledge increases when we use the input to textblob as all sentences which contain the word.
So, here in summary, we have analyzed sentiments on most similar words to some keywords and top-frequency words form the corpus.
It shows that using all sentences that contain a keyword is more essential than just the sentence with first occurrence of a word. The same was true in text frequencies experiments, as was in the experiments on similar words to describe the corpus.
Note there is slight variation in number of keywords used in both experiments.
The output show positive inclination. Also, on doing average we see that the sentiment is reduced to neutral sentiment. Hence it is neither positive nor negative. This shows the corpus in particuar have neutral sentiments on the topic of climate change. So, there are two ways to go in it. First, we can add some negative documents in corpus, or understand this is the sentiment on web. But we need to catch the fact that many people do write negative on social media about climate change. That is it but these 66,000 words in conjunction are of neutral opinion.
